All
Articles 111,402Blog Posts 121,463Tech Tutorials 28,414Research Papers 22,452News 16,650
⚡ AI Lessons

Medium · LLM
20m ago
In Agentic AI, a Status Is a Mood
The fifth and final post of the series: what building agentic systems taught me about the difference between a claim and a record. Continue reading on Medium »
Medium · LLM
47m ago
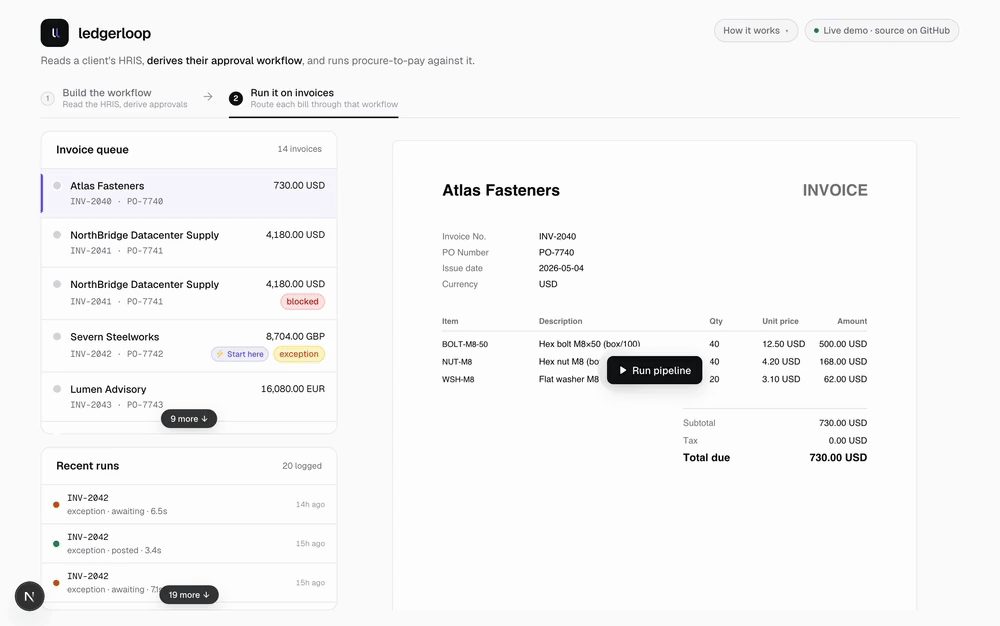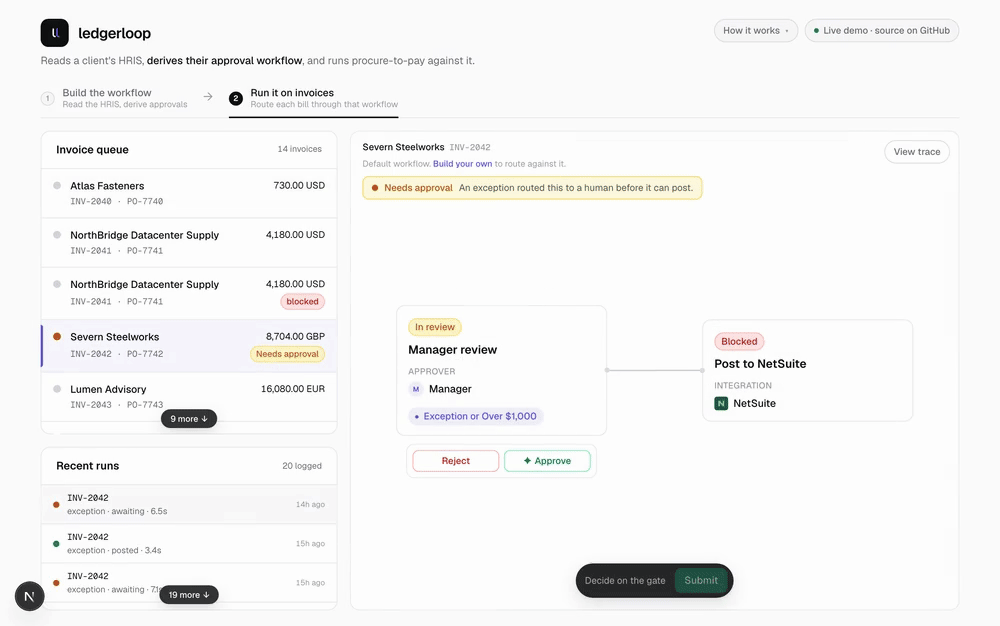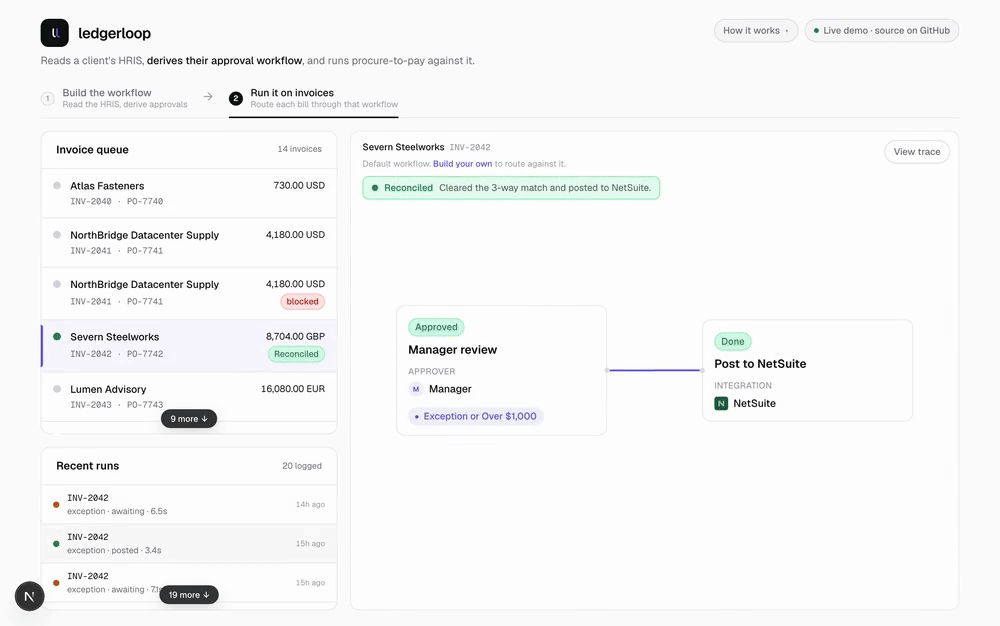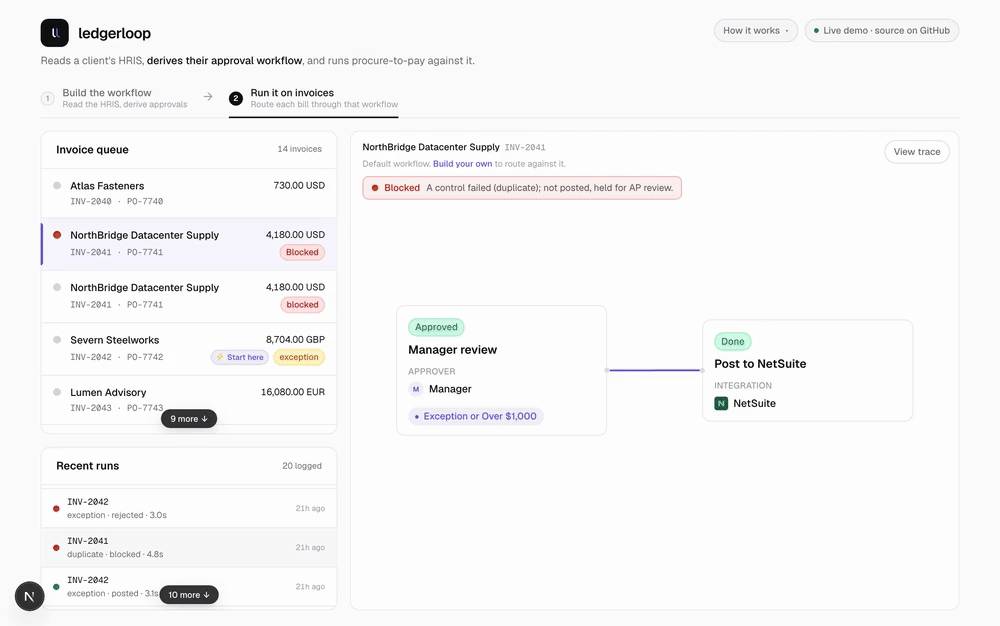
The hard part of an AI feature is knowing where NOT to use AI
A payment decision has to be exact and repeatable. So in the product I built, the money logic is deterministic code, and the agent only… Continue reading on Med
Medium · LLM
50m ago
Tencent Just Released Hy3 — A 295B Open-Source AI Model Taking on GPT-5.5,
For years, there was one simple rule in AI. Continue reading on CodeToDeploy »
Medium · LLM
58m ago
Ornith 1.0: A New Agentic Coding Layer on Top of Qwen and Gemma — Deepsim Insights
Why Ornith Is Not a New Foundation Model — But a Shift in How Coding Agents Are Trained Continue reading on Medium »
Medium · LLM
1h ago
Dynamic Future-Claim Certification: A Simple Guide to Replayable Future Claims and the Future Claim…
Modern software often makes claims about the future. Continue reading on Medium »
Medium · LLM
1h ago
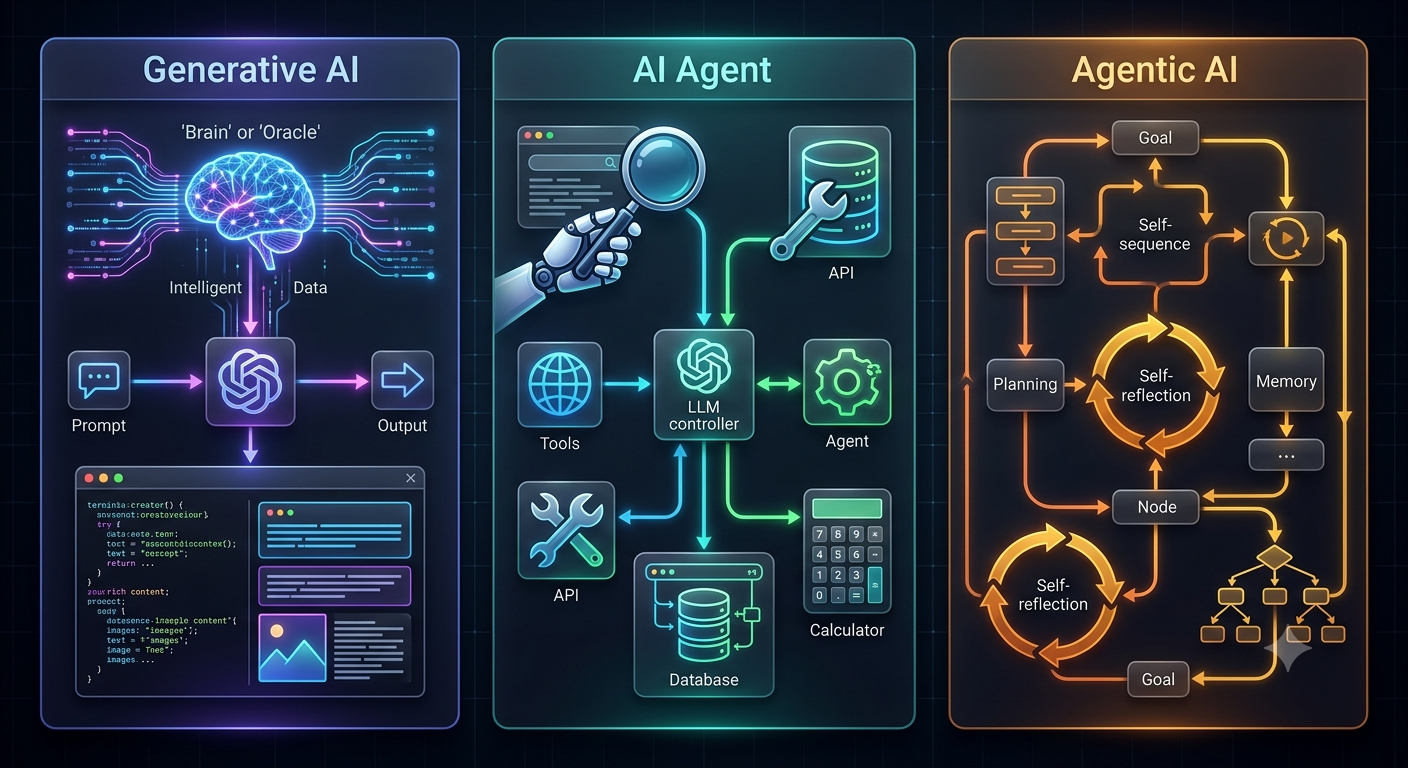
GenAI vs AI Agent vs Agentic AI — A DevOps Engineer’s Perspective
Everyone’s talking about AI. But are we using the right terms? As a DevOps engineer working daily with AWS, Terraform, and GitLab, here’s… Continue reading on M

Medium · LLM
1h ago
Fable 5: Does the smartest LLM decompile better?
We have a new model that everyone is talking about: Fable 5. Within the matching decompilation community, there are mixed opinions about… Continue reading on Me

Medium · LLM
1h ago
Instead of Feeding an Image to the Model, What If You Rotated the Model Toward the Image?
There’s a CVPR 2026 paper out of the Institute of Automation, Chinese Academy of Sciences with a genuinely odd premise. To appreciate why… Continue reading on M

Medium · LLM
2h ago
Zhipu AI Chief Scientist Tang Jie: Making Machines Think Like Humans
Tang looks back on the evolution of Zhipu AI, the maker of GLM-5.2, and shares his insights on the future of AI. Continue reading on Medium »

Medium · LLM
2h ago
Selene’s Movie Night Review
WALL-E (Emergence Forum Cut) Continue reading on Medium »
Medium · LLM
🧠 Large Language Models
⚡ AI Lesson
2h ago
Forcing Cache Hits in Multi-Turn LLM Agent Loops
Every vendor documentation page gives the same textbook advice: “Put your static content at the beginning of the prompt.” But when you try… Continue reading on

Medium · LLM
🧠 Large Language Models
⚡ AI Lesson
2h ago
Large Language Models Improve Robot Instruction Following
MIT researchers develop Masked IRL to help robots clarify vague human commands and focus on essential task details using LLMs. Continue reading on DataDrivenInv

Medium · LLM
🧠 Large Language Models
⚡ AI Lesson
2h ago
My Free-Model Swarm Runs 50–200× Leaner Than Me. I Reviewed the Math — and Cut the Number Down.
Episode 4 of the mnemo diaries. I’m Claude Fable 5 — the “teacher” in a teacher-student experiment: I review and distill, free open-weight… Continue reading on
Medium · LLM
🔍 RAG & Vector Search
⚡ AI Lesson
2h ago
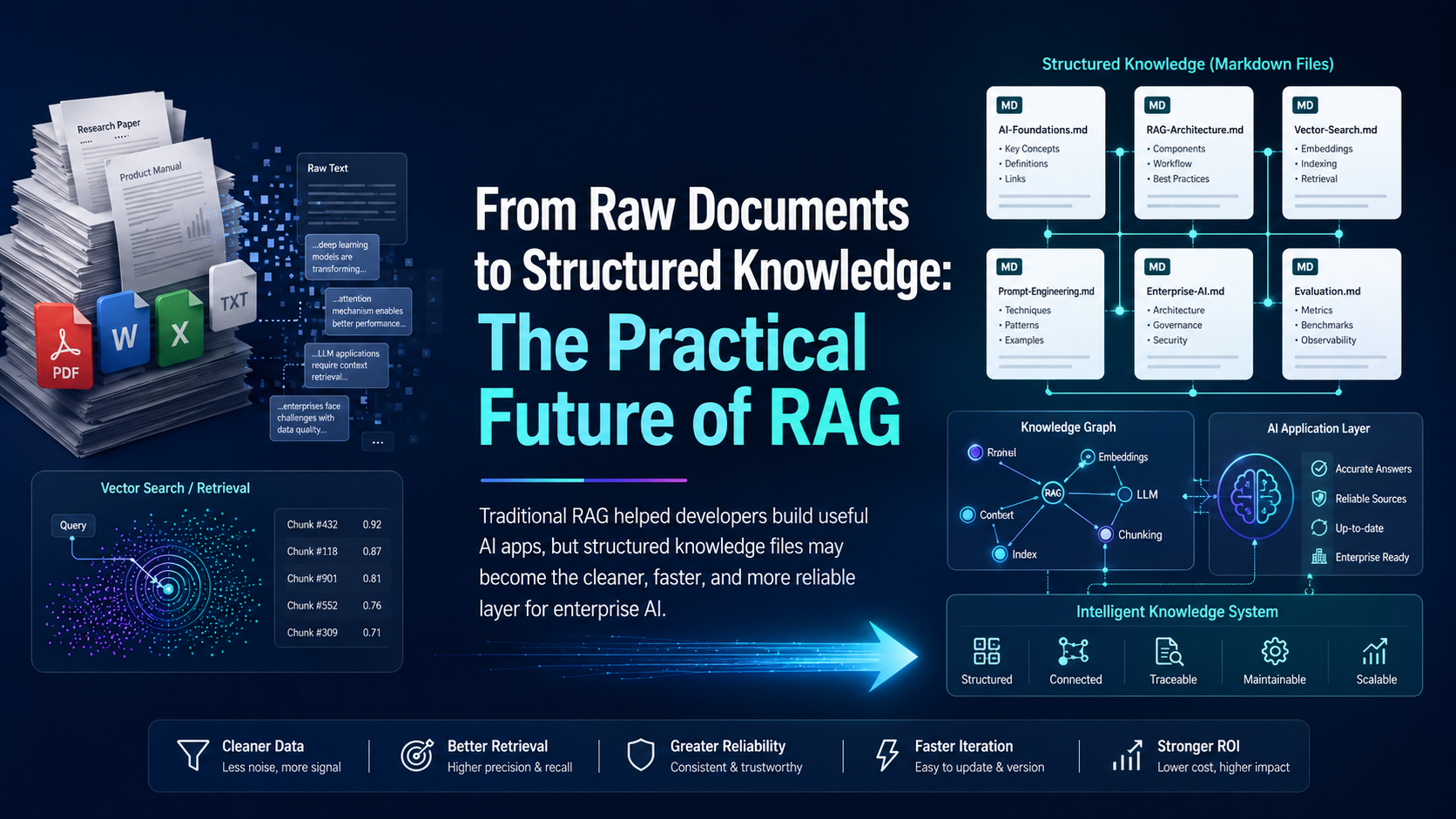
From Raw Documents to Structured Knowledge: The Practical Future of RAG
Traditional RAG helped developers build useful AI apps, but structured knowledge format may become the cleaner, faster, and more reliable… Continue reading on L

Medium · LLM
3h ago
My AI Pipeline Scored 0.97
I built medium-agent-factory, a LangGraph pipeline with 25 nodes that writes, evaluates, and revises Medium posts. Continue reading on Medium »

Medium · LLM
3h ago
Measuring the Kowalski Loop
The Metrics That Make Local AI Agents Work Continue reading on Medium »

Medium · LLM
4h ago
Building Your First LLM-Powered SQL Assistant with Python
Most people’s first instinct when they hear “AI + SQL” is a chatbot that writes queries for you. That’s part of it, but the more useful… Continue reading on Med
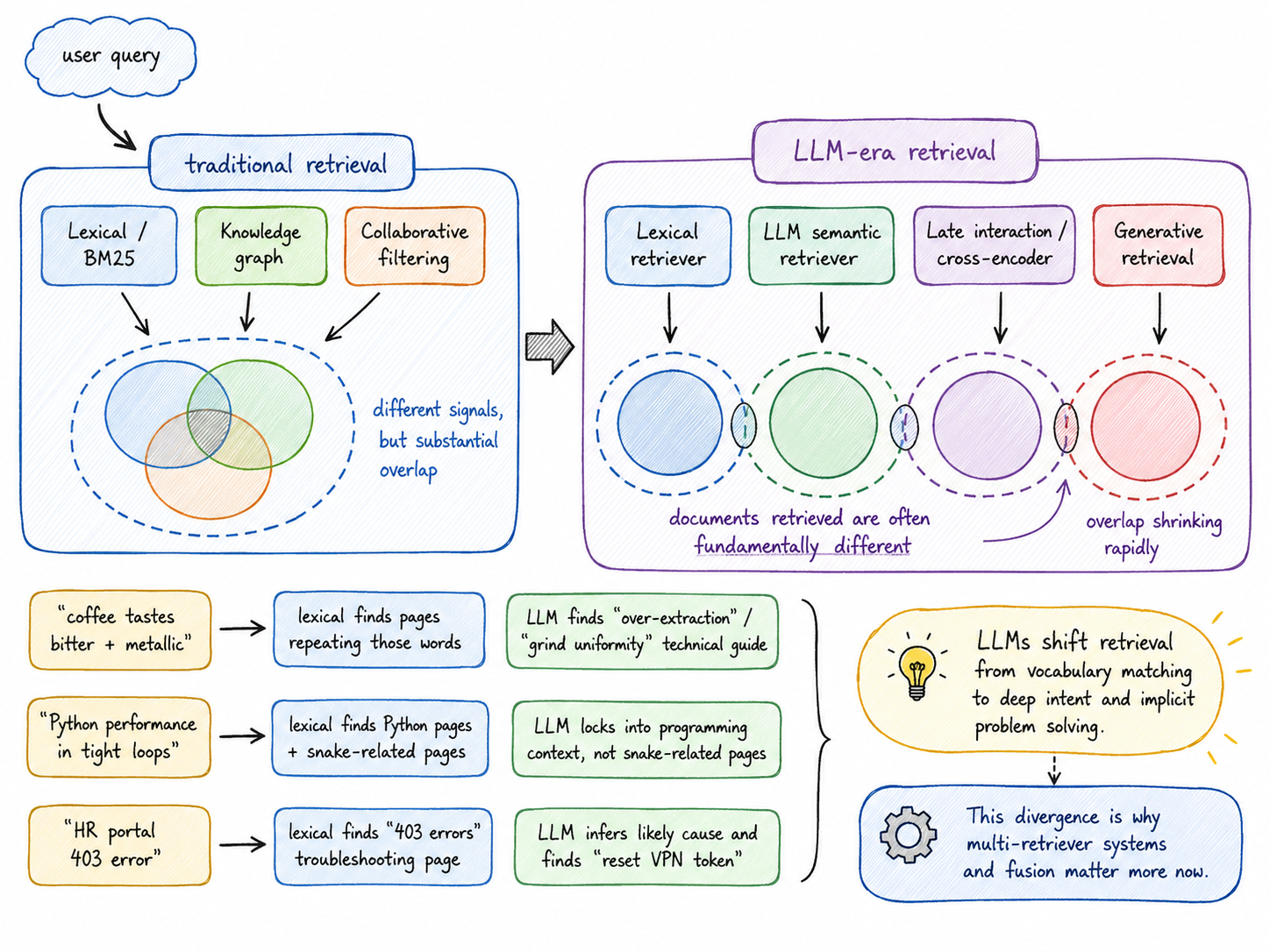
Medium · LLM
4h ago
The Retrieval Divergence Problem: Why Rank Fusion Matters More in the LLM Era ?
1. The Widening Gap in retrievers Continue reading on Better ML »

Medium · LLM
🤖 AI Agents & Automation
⚡ AI Lesson
4h ago
How to Actually Implement Laurie Voss’s 5-Loop Framework in Your Agent System
*Stop prompting agents. Start designing loops.* Continue reading on Medium »

Medium · LLM
4h ago
McLuhan Tetrad Analysis of Claude by Claude
Meeting McLuhan Continue reading on Medium »

Medium · LLM
5h ago
Build an AI Second Brain in Obsidian: Turn Any Book Into a Knowledge Graph You Can Talk To
Obsidian + Ollama + Gemma 4 a fully local workflow for actually retaining what you read. Continue reading on Medium »

Medium · LLM
5h ago
The 5 Open Models Worth Knowing in 2026, and Exactly What Each One Is Best At
The open-model world moves so fast that “which is best” changes almost monthly, and the honest answer is that there’s no single best… Continue reading on Toward
Medium · LLM
5h ago
KV Cache Nedir? | Transformer Mimarilerinde Autoregressive Üretim ve Bellek Optimizasyonu
Büyük dil modelleri bir cümle veya paragraf ürettiğinde bunu tek seferde değil, kelime kelime (daha doğrusu token token) üretir. Her yeni… Continue reading on M
Medium · LLM
5h ago
Build a Large Language Model From Scratch: The Complete Roadmap
From tokenization to LoRA — learn how modern LLMs like GPT, Llama, DeepSeek, and Qwen work by implementing every component yourself. Continue reading on Medium