All
Articles 116,963Blog Posts 125,031Tech Tutorials 29,889Research Papers 23,513News 17,250
⚡ AI Lessons
Ahead of AI
🤖 AI Agents & Automation
⚡ AI Lesson
1w ago
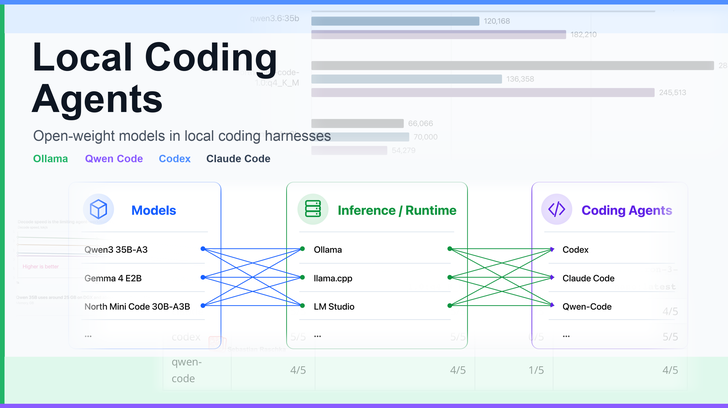
Using Local Coding Agents
Using Open-Weight Models in Local Coding Harnesses as an Alternative to Claude Code and Codex Subscriptions
Ahead of AI
1mo ago
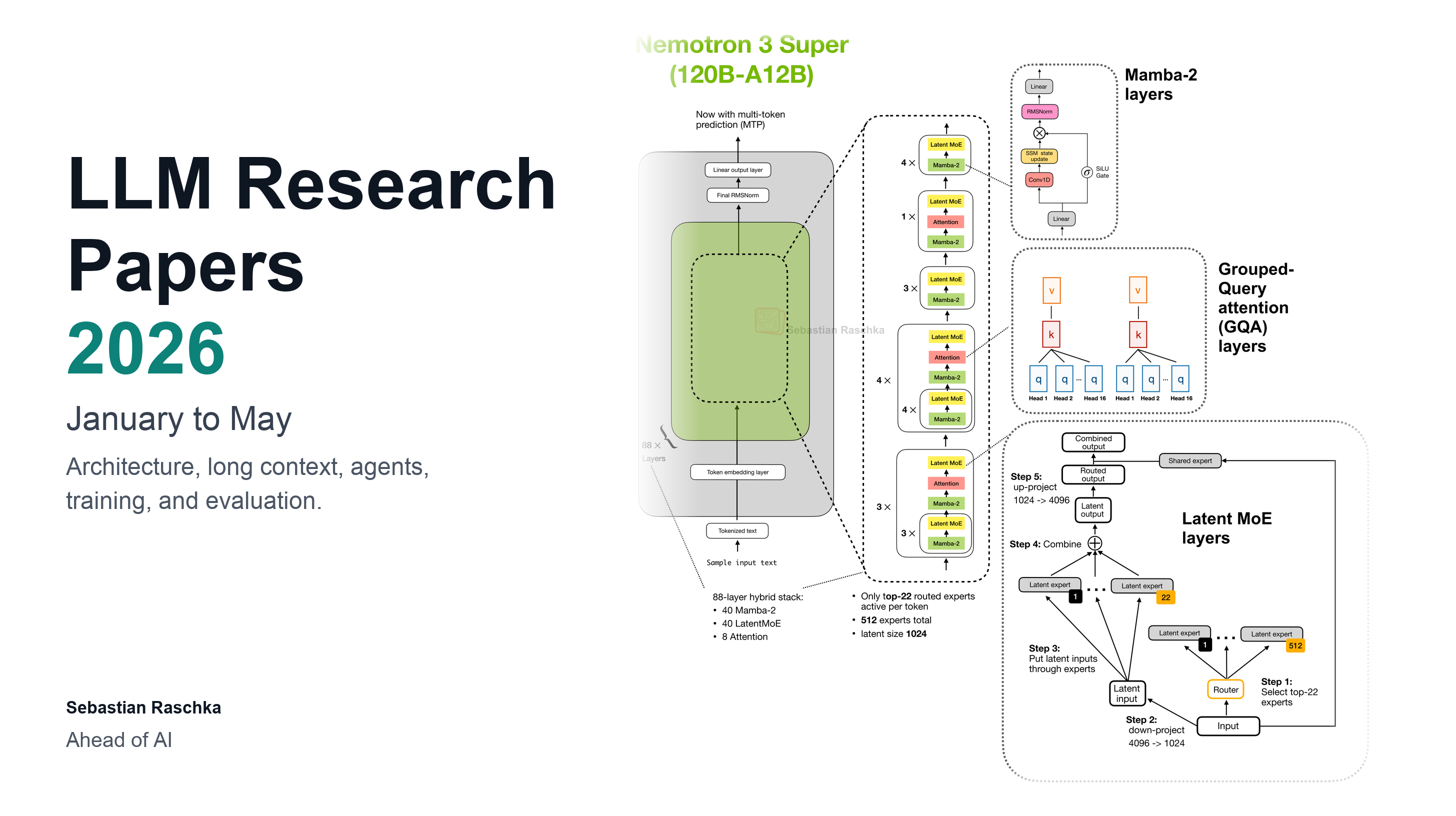
LLM Research Papers: The 2026 List (January to May)
A curated roundup of notable LLM research papers that came out this year

Ahead of AI
1mo ago
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed Attention
From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs
Ahead of AI
2mo ago
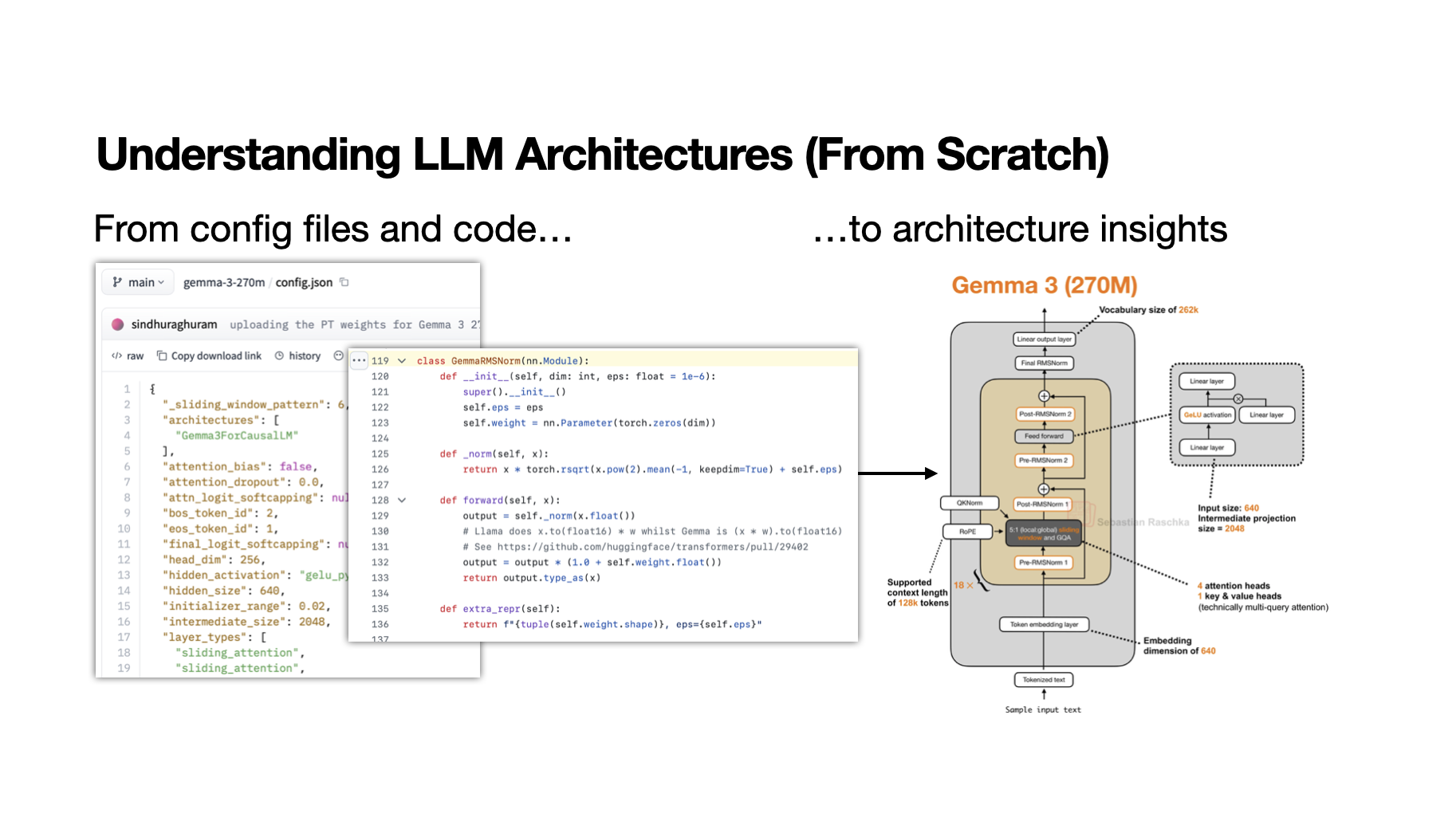
My Workflow for Understanding LLM Architectures
A learning-oriented workflow for understanding new open-weight model releases
Ahead of AI
🤖 AI Agents & Automation
⚡ AI Lesson
3mo ago
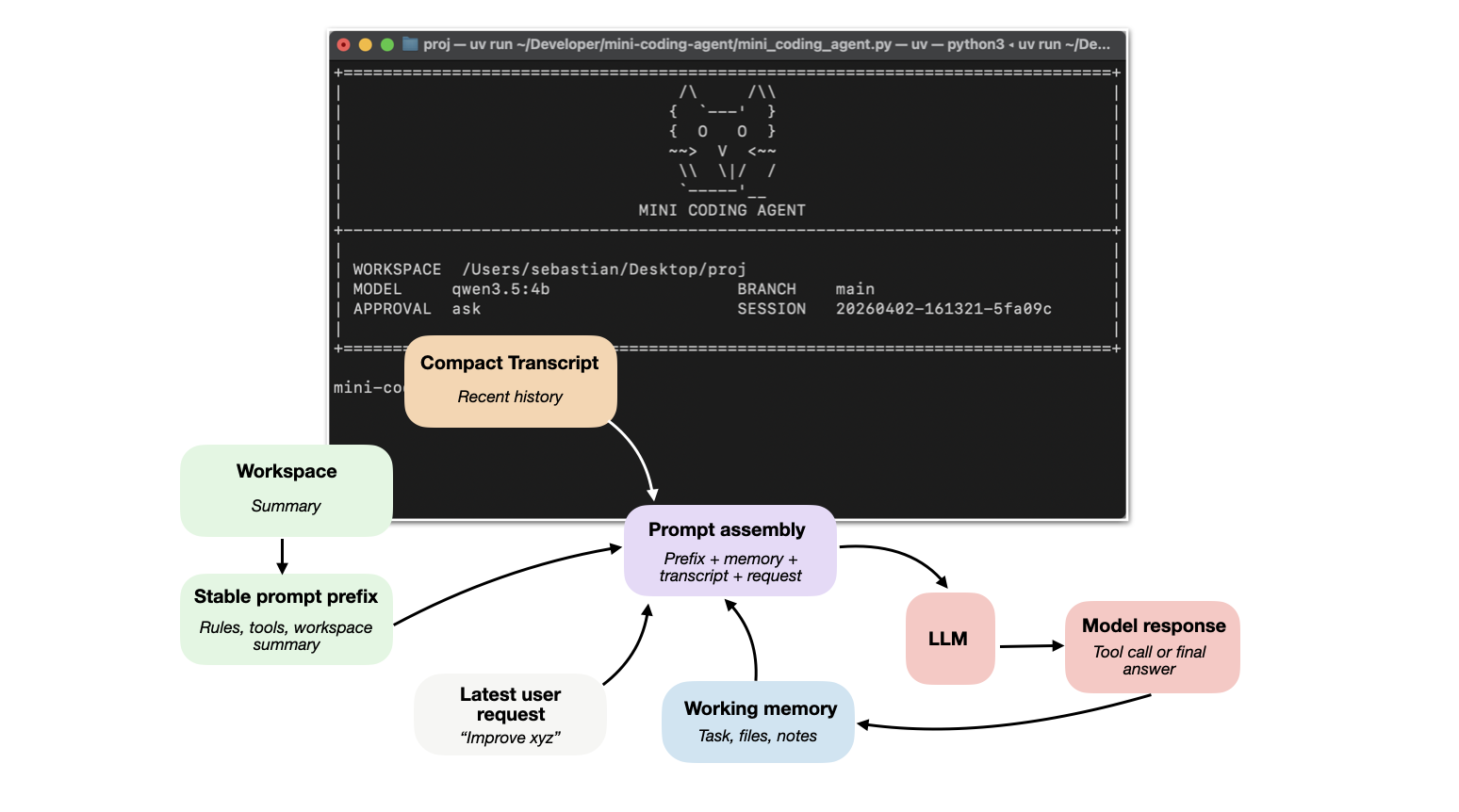
Components of A Coding Agent
How coding agents use tools, memory, and repo context to make LLMs work better in practice

Ahead of AI
3mo ago
A Visual Guide to Attention Variants in Modern LLMs
From MHA and GQA to MLA, sparse attention, and hybrid architectures
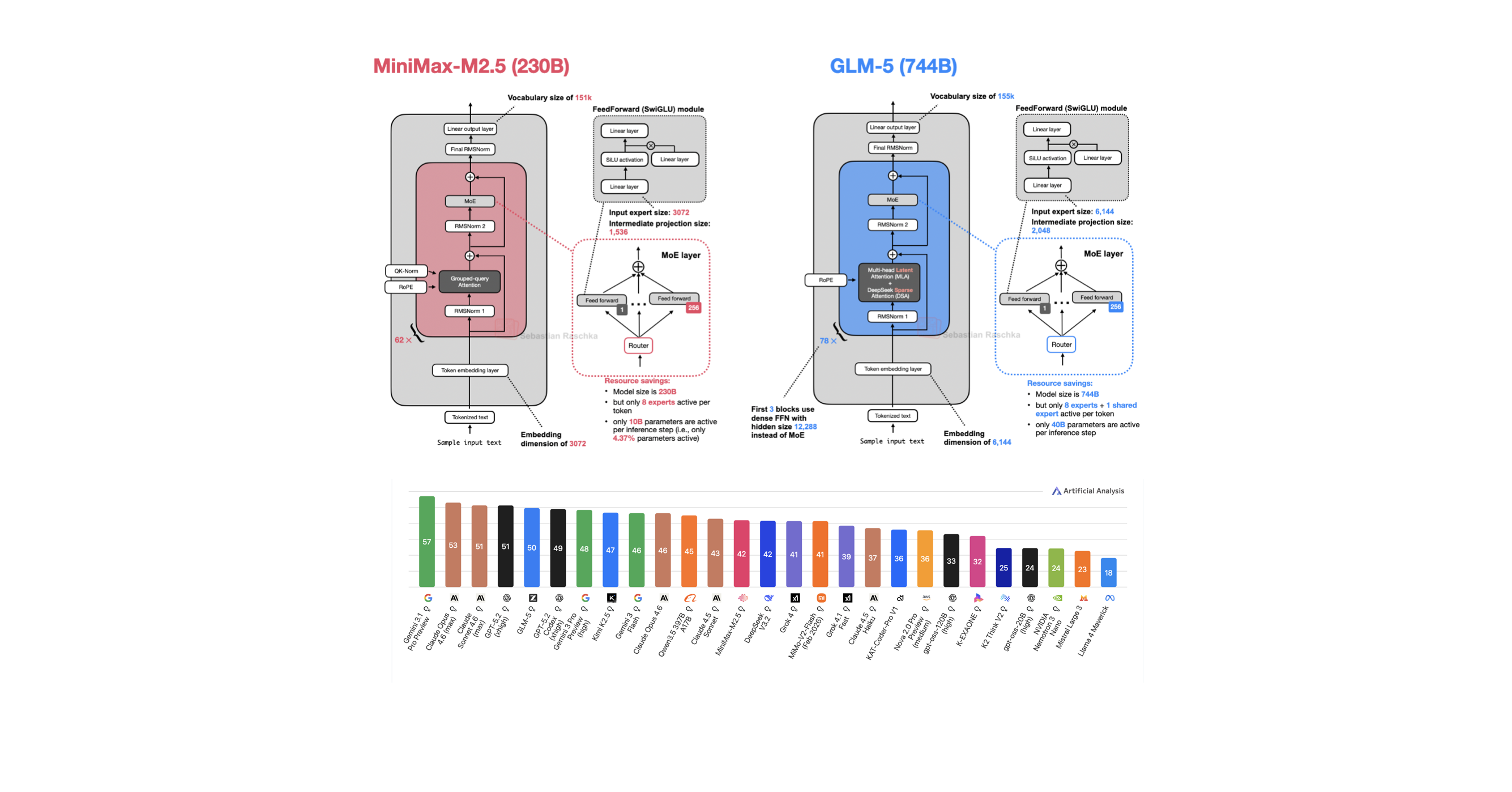
Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
4mo ago
A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
Ahead of AI
5mo ago
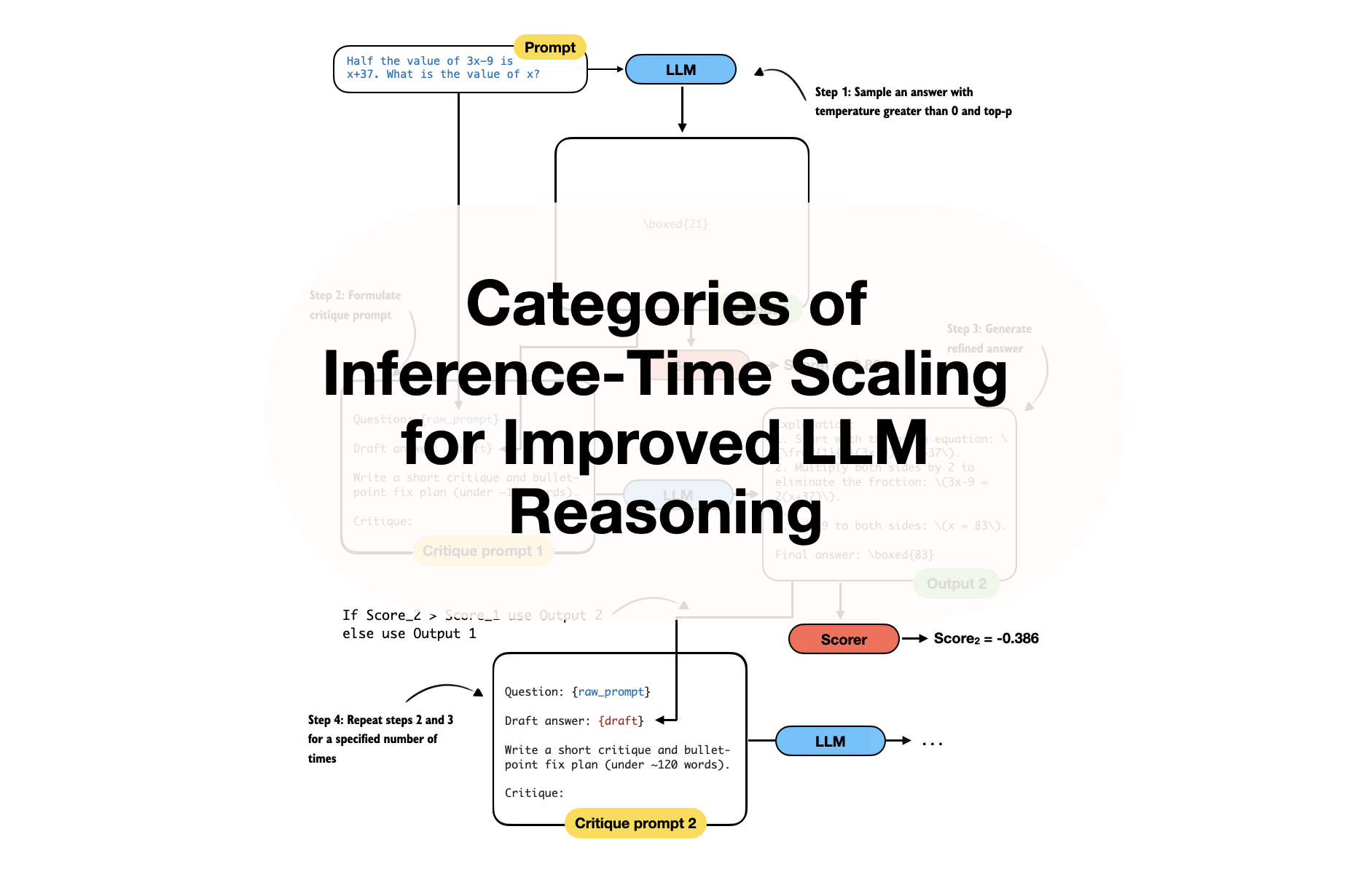
Categories of Inference-Time Scaling for Improved LLM Reasoning
And an Overview of Recent Inference-Scaling Papers
Ahead of AI
6mo ago
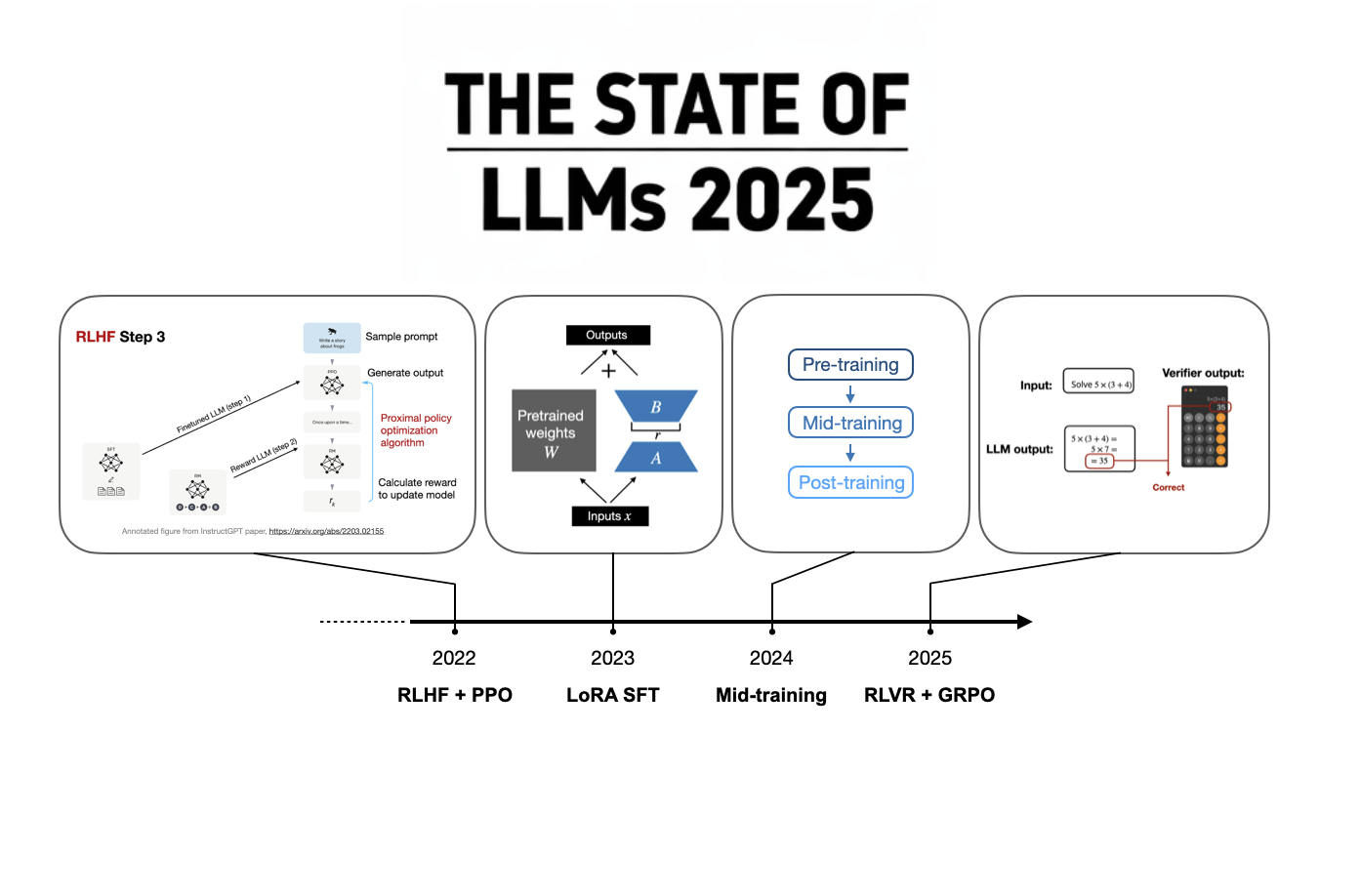
The State Of LLMs 2025: Progress, Problems, and Predictions
A 2025 review of large language models, from DeepSeek R1 and RLVR to inference-time scaling, benchmarks, architectures, and predictions for 2026.
Ahead of AI
6mo ago
LLM Research Papers: The 2025 List (July to December)
In June, I shared a bonus article with my curated and bookmarked research paper lists to the paid subscribers who make this Substack possible.
Ahead of AI
7mo ago
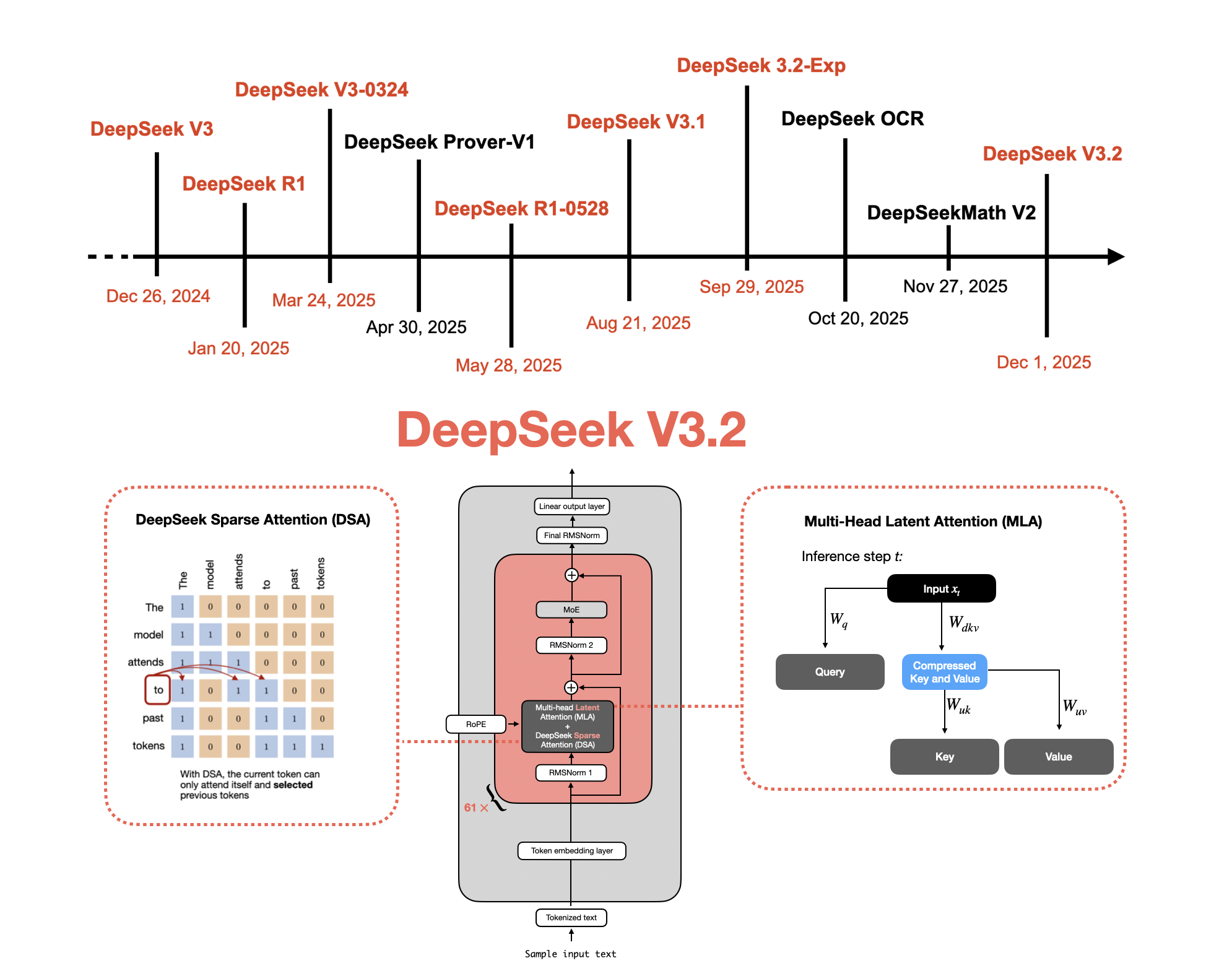
From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates
Understanding How DeepSeek's Flagship Open-Weight Models Evolved
Ahead of AI
8mo ago
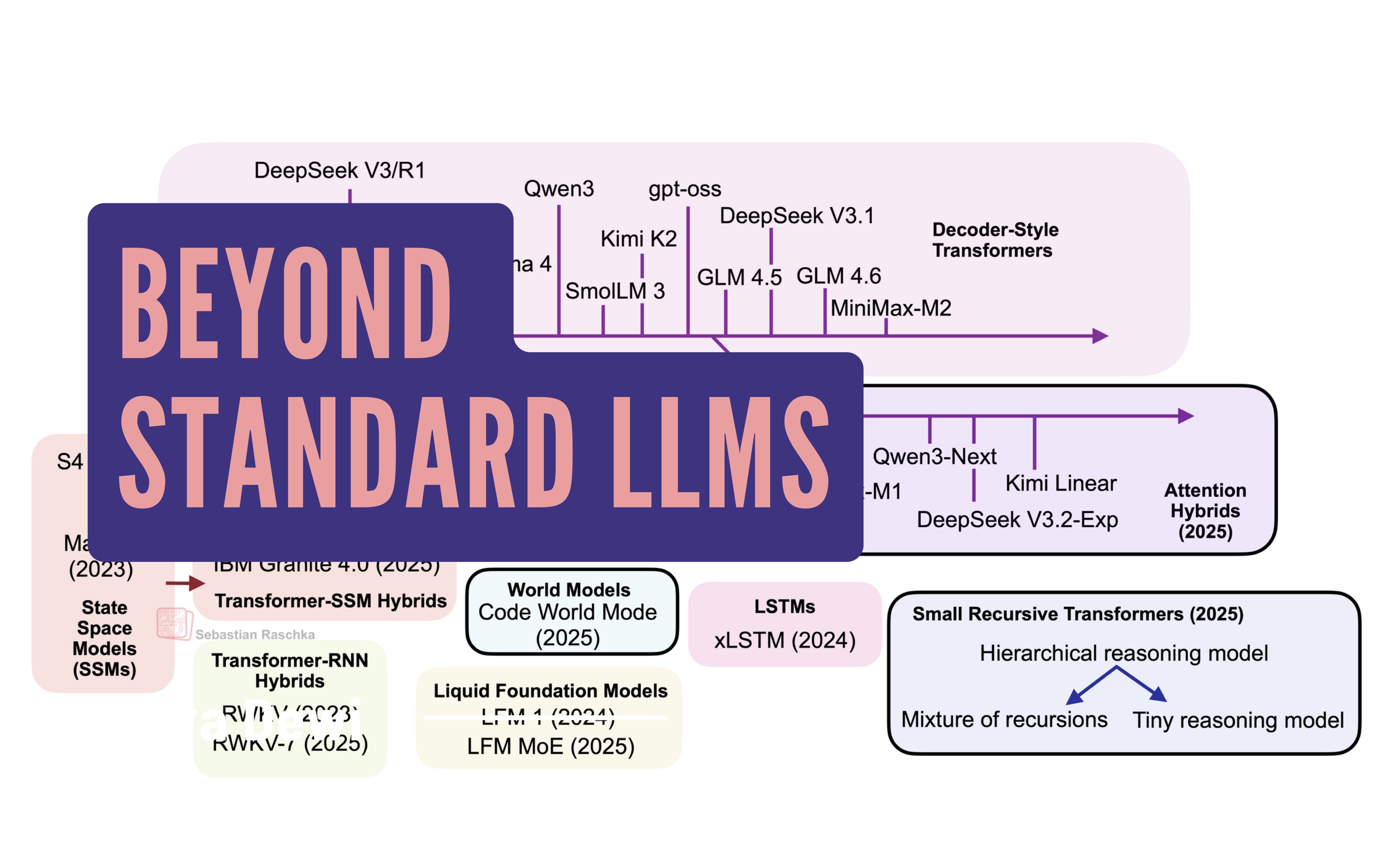
Beyond Standard LLMs
Linear Attention Hybrids, Text Diffusion, Code World Models, and Small Recursive Transformers
Ahead of AI
9mo ago
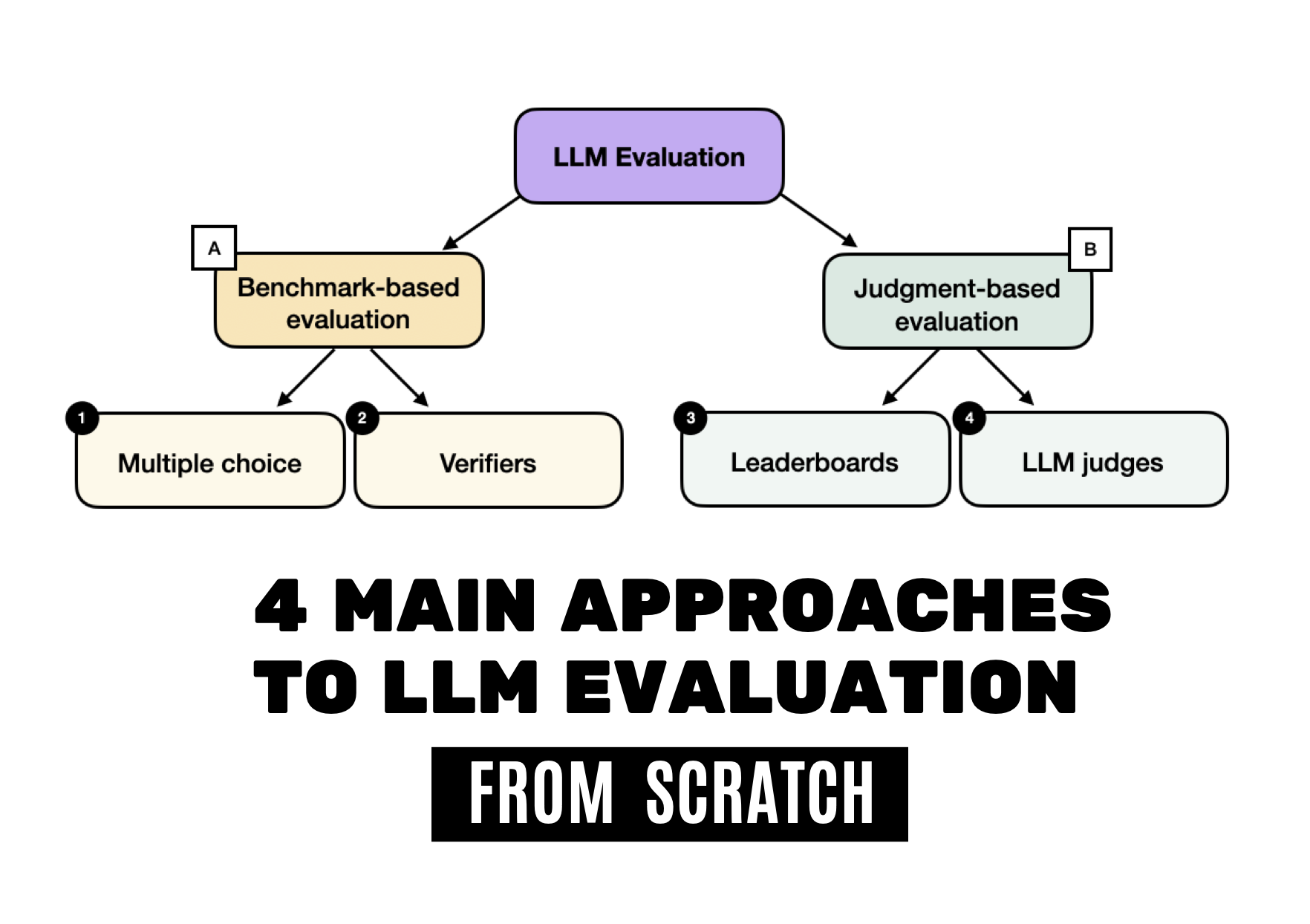
Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples
Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
10mo ago
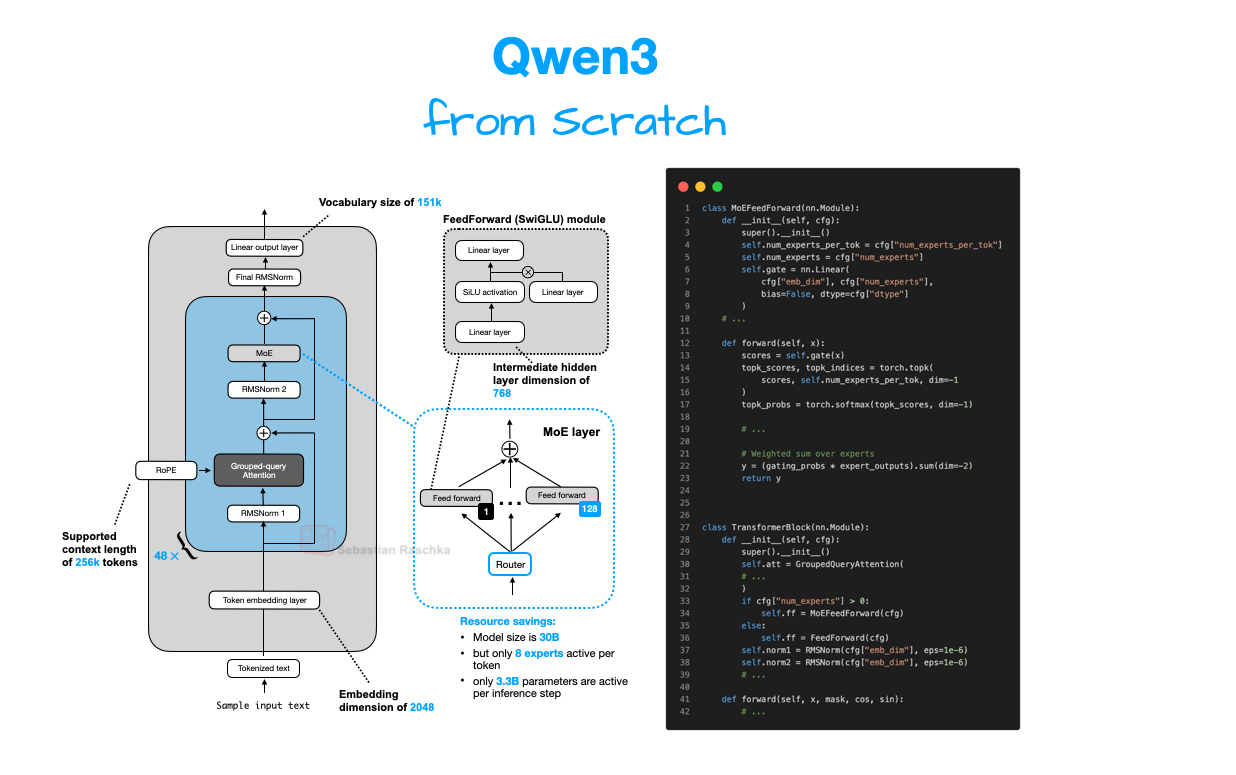
Understanding and Implementing Qwen3 From Scratch
A Detailed Look at One of the Leading Open-Source LLMs
Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
1y ago
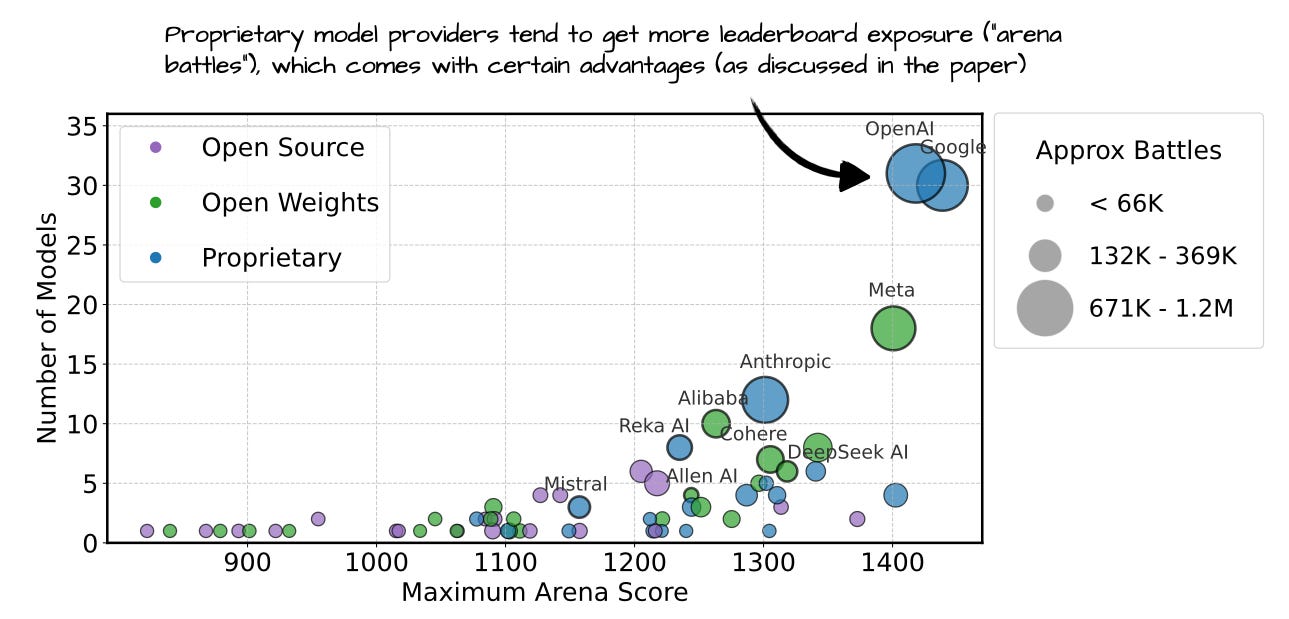
LLM Research Papers: The 2025 List (January to June)
A topic-organized collection of 200+ LLM research papers from 2025
Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
1y ago
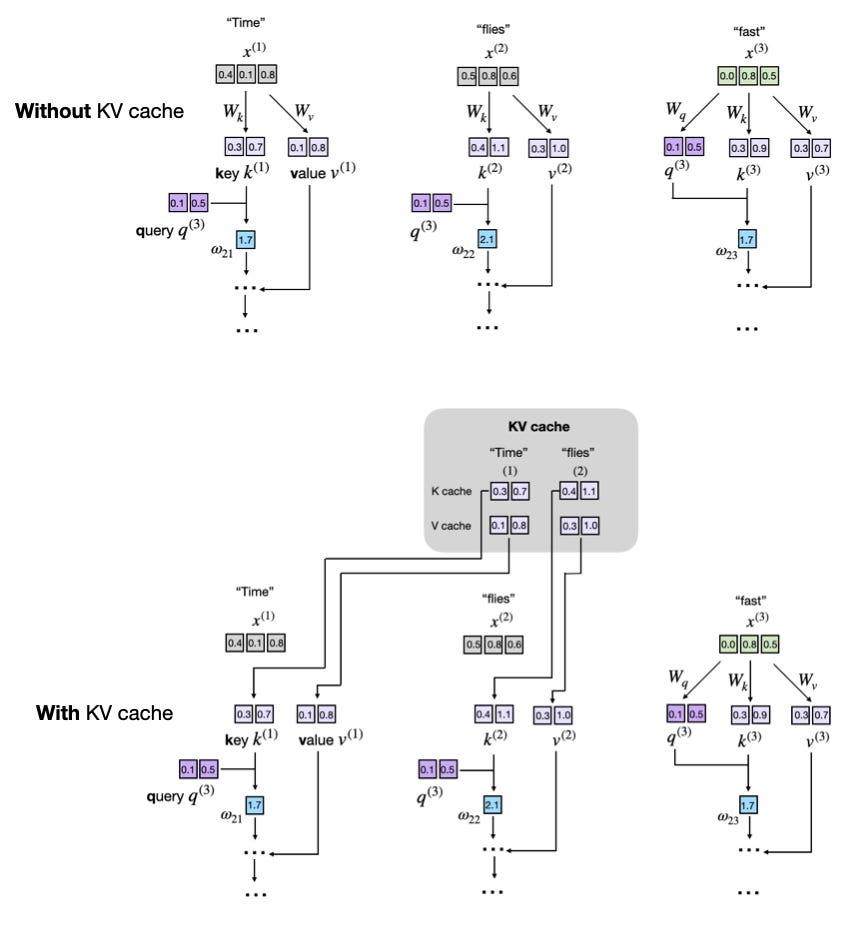
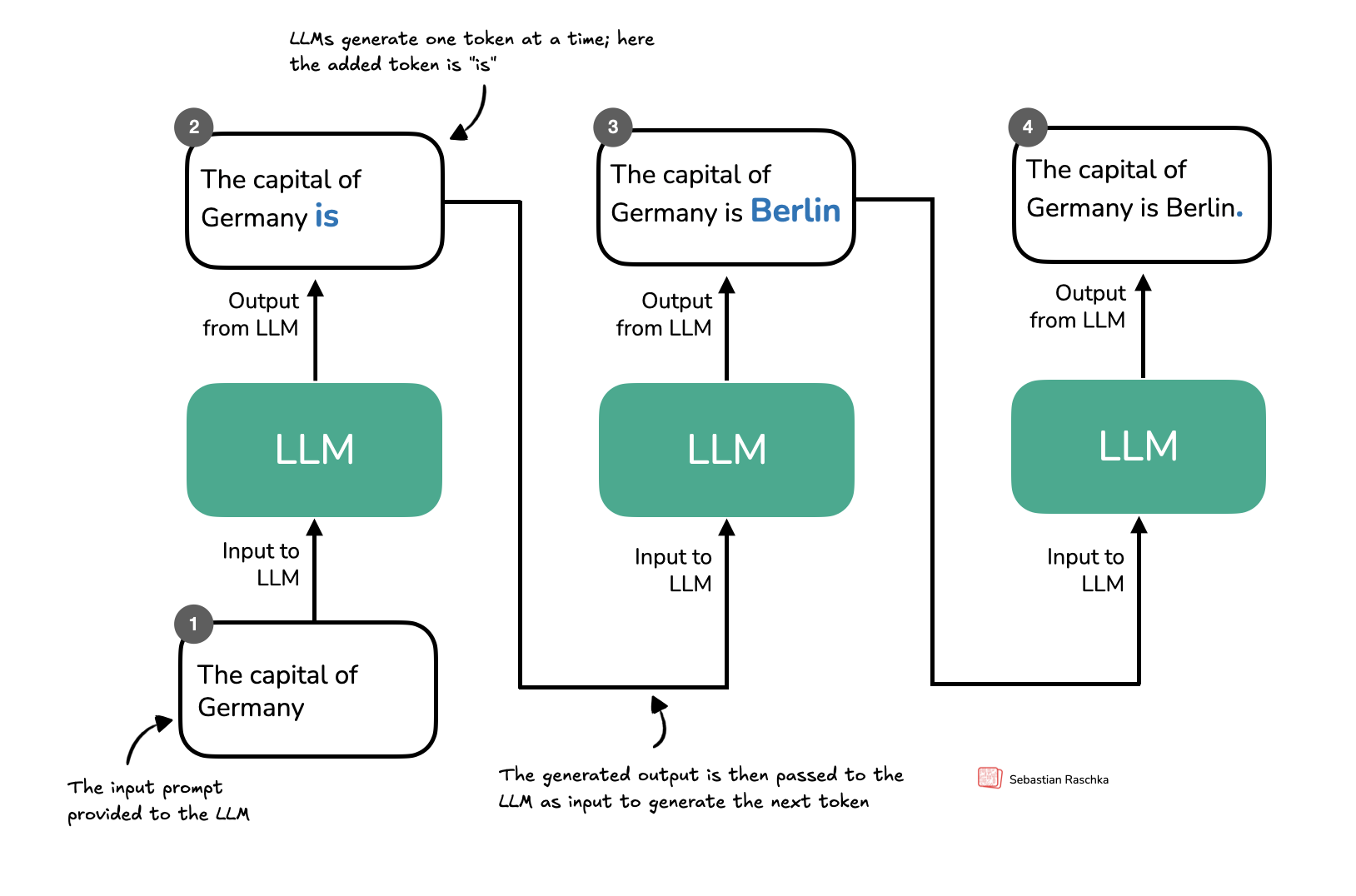
Understanding and Coding the KV Cache in LLMs from Scratch
KV caches are one of the most critical techniques for efficient inference in LLMs in production.
Ahead of AI
1y ago
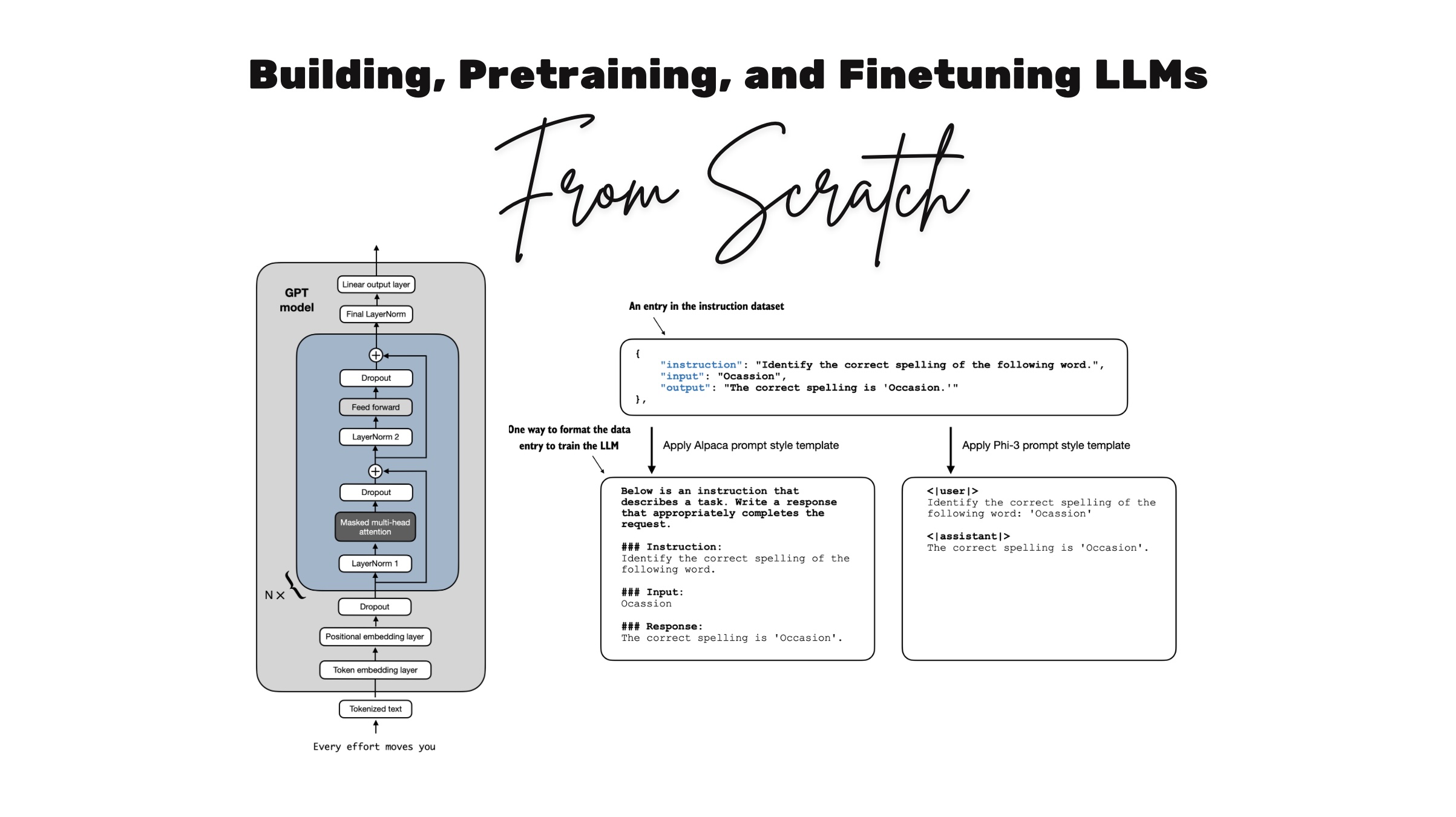
Coding LLMs from the Ground Up: A Complete Course
Why build LLMs from scratch? It's probably the best and most efficient way to learn how LLMs really work. Plus, many readers have told me they had a lot of fun
Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
1y ago
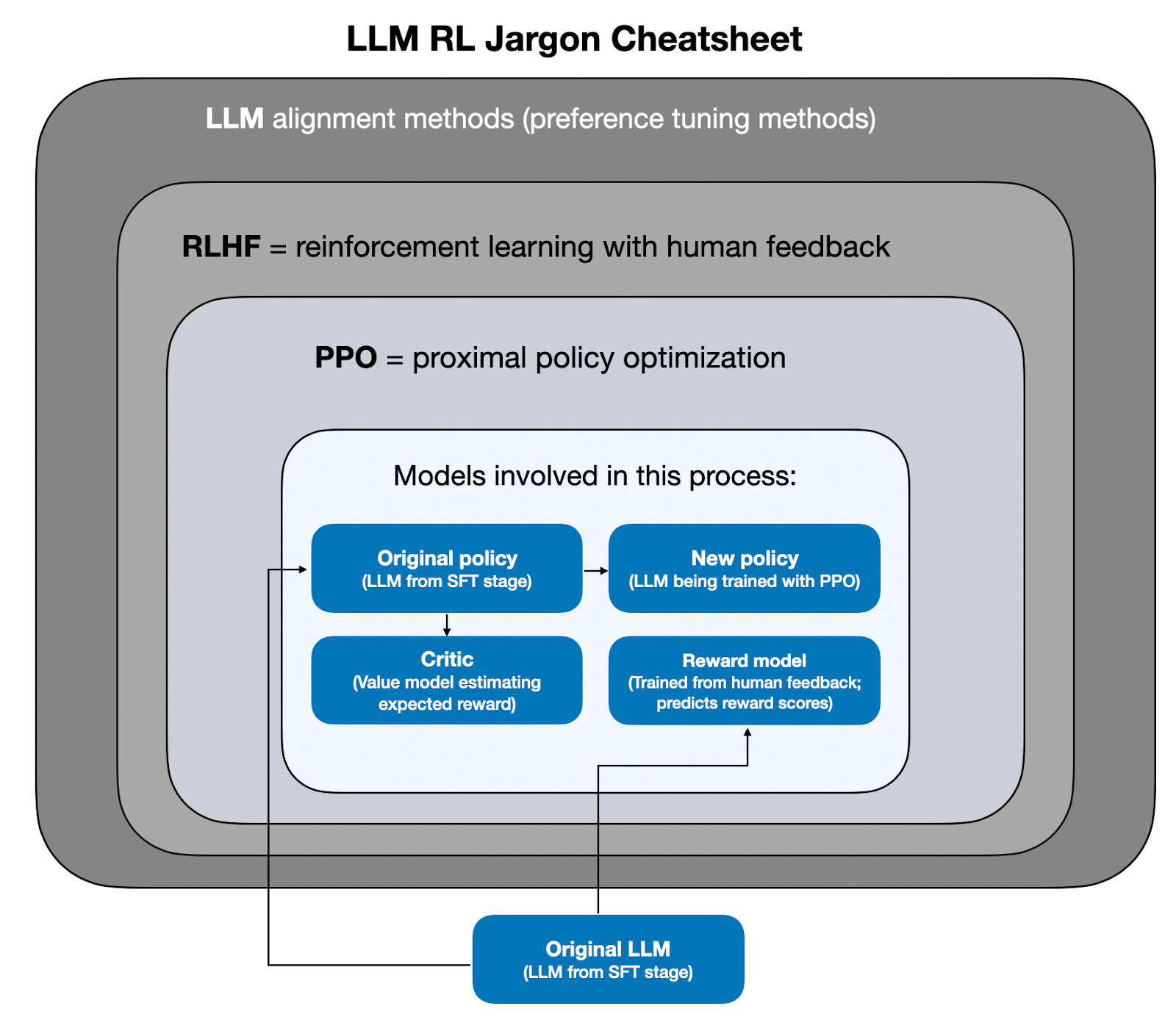
The State of Reinforcement Learning for LLM Reasoning
Understanding GRPO and New Insights from Reasoning Model Papers
Ahead of AI
1y ago
First Look at Reasoning From Scratch: Chapter 1
Welcome to the next stage of large language models (LLMs): reasoning. LLMs have transformed how we process and generate text, but their success has been largely

Ahead of AI
🧠 Large Language Models
⚡ AI Lesson
1y ago
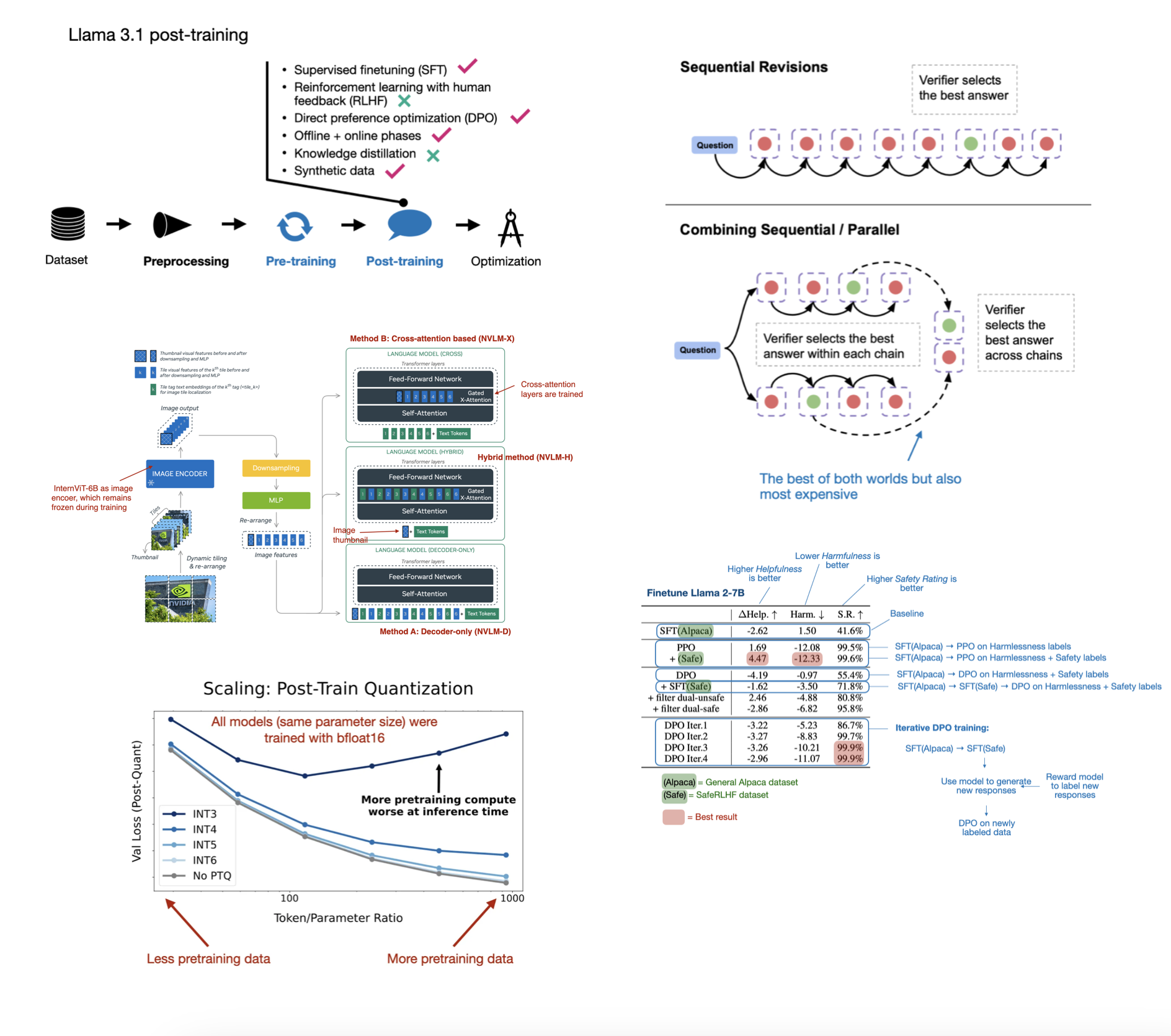
The State of LLM Reasoning Model Inference
Inference-Time Compute Scaling Methods to Improve Reasoning Models
Ahead of AI
1y ago
Noteworthy AI Research Papers of 2024 (Part Two)
Six influential AI papers from July to December