Foundations
Computer Vision
Object detection, segmentation, YOLO, CLIP, and vision-language models
Skills in this topic
3 skills — Sign in to track your progress

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1w ago
July 9 — Best of CVPR (Day 2)
Join us on July 9 for day 2 of the “Best of CVPR” series. Continue reading on Voxel51 »
Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
1w ago
July 9 — Best of CVPR (Day 2)
Join us on July 9 for day 2 of the “Best of CVPR” series. Continue reading on Voxel51 »

Dev.to · Nagesh K
👁️ Computer Vision
⚡ AI Lesson
1w ago
The Beginner’s Guide to Private vs Public IPs, Ex - Banking Systems
When I first studied IP addresses, I thought: “Private IPs are only inside my router, and public IPs...
The Verge
👁️ Computer Vision
⚡ AI Lesson
1w ago
Star Fox is the Switch 2’s most impressive visual showcase yet
The biggest Switch 2 exclusives so far have largely been about scale. Mario Kart World introduced a wide open continent to race across, Donkey Kong Bananza let

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1w ago
SpatialClaw: Decoding Spatial Reasoning
When we look at a room, we instantly understand where things are. We know the chair is next to the table. If a ball rolls across the floor… Continue reading on
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
CineCap: Structured Reasoning with Spatio-Temporal Anchors for Cinematographic Video Captioning
arXiv:2606.24636v1 Announce Type: new Abstract: Cinematographic captioning aims to describe how a video is filmed using professional film-language concepts such
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
From Spatial to Spectral: An Efficient, Frequency-Guided Feature Representation Learner for Small Object Detection
arXiv:2606.23825v1 Announce Type: cross Abstract: Efficient small object detection is bottlenecked by the inherent feature scarcity of tiny targets, which is fu
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Beyond Bayer: Task-Optimal Sensor Co-Design for Robust Autonomous-Driving Segmentation
arXiv:2606.24096v1 Announce Type: cross Abstract: Robust perception underpins autonomous driving, and most recent progress comes from scaling the model-larger b
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Zero-Shot Test-Time Canonicalization using Out-of-Distribution Scoring
arXiv:2606.24178v1 Announce Type: cross Abstract: Pretrained vision models often misclassify inputs that are rotated, scaled, or sheared, even though these affi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
FLUX3D: High-Fidelity 3D Gaussian Generation with Diffusion-Aligned Sparse Representation
arXiv:2606.24874v1 Announce Type: cross Abstract: Sparse voxel representation has emerged as a scalable foundation for image-to-3D Gaussian Splatting (3DGS) gen
Dev.to AI
👁️ Computer Vision
⚡ AI Lesson
1w ago
Real-Time Gesture Controlled Invisibility Cloak in Python (MediaPipe & OpenCV)
Build a Real-Time Gesture Controlled Invisibility Cloak using Python, MediaPipe, and OpenCV! 🪄💻 In this computer vision tutorial, we are creating an interacti

Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1w ago
How I Built a Face Detection Web App in Python in Under 20 Minutes (And You Can Too)
A step-by-step guide to deploying your first Computer Vision AI project using OpenCV and Streamlit. Continue reading on Medium »
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
1w ago
How I Built a Face Detection Web App in Python in Under 20 Minutes (And You Can Too)
A step-by-step guide to deploying your first Computer Vision AI project using OpenCV and Streamlit. Continue reading on Medium »
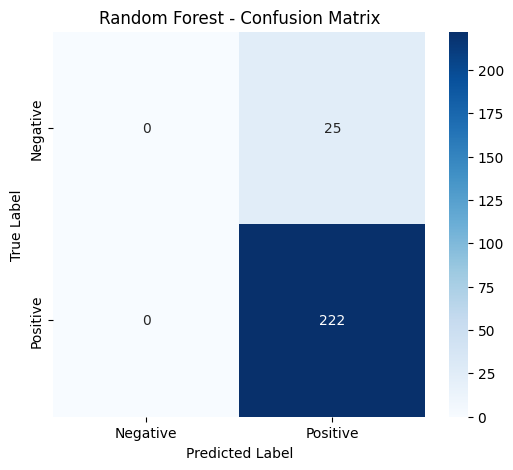
Medium · Machine Learning
👁️ Computer Vision
⚡ AI Lesson
1w ago
I Had 54 Underwater Images and Needed a Reliable Corrosion Detector
Here’s What Actually Worked Continue reading on Medium »
Medium · Data Science
👁️ Computer Vision
⚡ AI Lesson
1w ago
I Had 54 Underwater Images and Needed a Reliable Corrosion Detector
Here’s What Actually Worked Continue reading on Medium »

Dev.to · humnaattique4-sys
👁️ Computer Vision
⚡ AI Lesson
1w ago
What I Learned About 3D Reconstruction — My First Week at PreserveMy.World
I just started my internship at PreserveMy.World, a project focused on digitally preserving cultural...

Dev.to · Saurin Prajapati
👁️ Computer Vision
⚡ AI Lesson
1w ago
Splitting Face Recognition Across the Edge and the Cloud with AWS IoT Greengrass + Lambda
How I built a real-time face recognition pipeline that detects faces at the edge on AWS IoT Greengrass and recognizes them serverlessly with Lambda, glued toget

Dev.to · Elise Moreau
👁️ Computer Vision
⚡ AI Lesson
1w ago
A VLM gate for generated images, with provider failover via Bifrost
TL;DR: At Photoroom we run a vision-language model as the last check before a generated product image...
Dev.to · Alan Scott Encinas
👁️ Computer Vision
⚡ AI Lesson
1w ago
I entered a competition to track objects in light you can't see
The first entry in a live builder's log. I'm competing in the Hyperspectral Object Tracking Challenge 2026: track one object through video shot in colors the hu
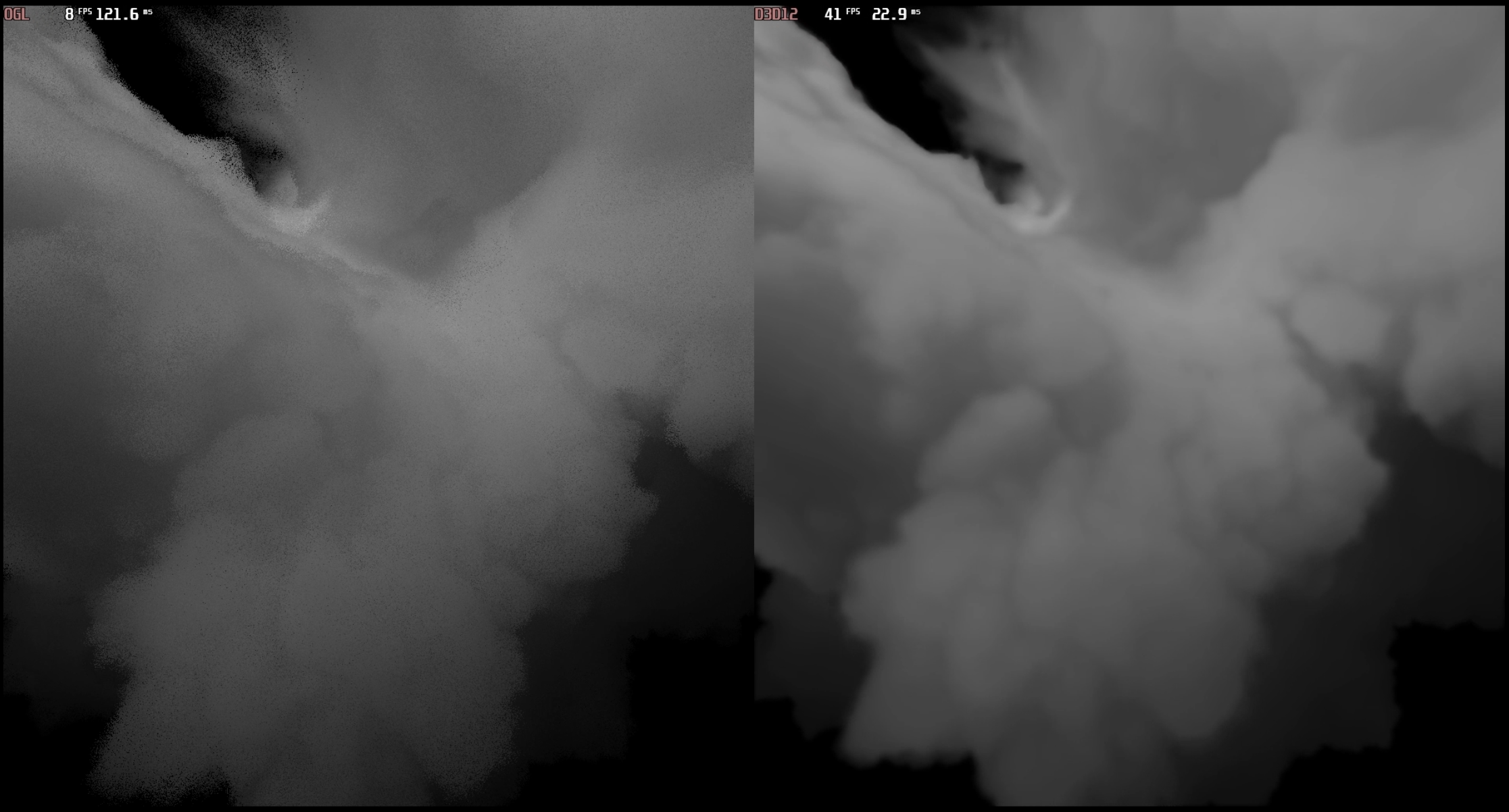
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
1w ago
Tiled-MRPNN — real-time photorealistic light transport in participating media
Historically, real-time light transport in participating media has mainly been handled with simplified physics simulations and crude… Continue reading on Medium
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Automatic Vehicle Detection using DETR: A Transformer-Based Approach for Navigating Treacherous Roads
arXiv:2502.17843v1 Announce Type: cross Abstract: Automatic Vehicle Detection (AVD) in diverse driving environments presents unique challenges due to varying li
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
GEOPHYS: The Geometry of Physical Plausibility
arXiv:2606.20707v1 Announce Type: cross Abstract: While humans can identify physically implausible events within milliseconds, machine learning approaches addre
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
XmoPipe: A Pipeline for Large-Scale In-the-Wild Human Motion Dataset Construction
arXiv:2606.20731v1 Announce Type: cross Abstract: Large-scale human motion datasets are essential for training robust motion models for analysis, synthesis, and
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
UniSLAD: A Unified Framework for Structural and Logical Industrial Visual Anomaly Detection
arXiv:2606.20768v1 Announce Type: cross Abstract: Visual anomaly detection is a fundamental task in industrial automation. While existing approaches have achiev
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
GroundShot: Visually Consistent Multi-Shot Long Video Generation via Entity-Grounded Shot Scheduling
arXiv:2606.20799v1 Announce Type: cross Abstract: Generating visually consistent multi-shot videos remains an open challenge. As videos span more shots, inconsi
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
MS-rPPG: Multi-spectral State Space Model for Remote Photoplethysmography in Driver Monitoring Systems
arXiv:2606.21115v1 Announce Type: cross Abstract: Remote photoplethysmography (rPPG) is a camera-based technique for measuring physiological signals, particular
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
ACE-GS: Acing the Trade-off with Accurate, Compact and Efficient 3D Gaussian Splatting
arXiv:2606.21244v1 Announce Type: cross Abstract: 3D Gaussian Splatting achieves exceptional real-time rendering, but its substantial computational and storage
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Scene-Level Heterogeneous Physics Simulation with 3D Gaussian Splats
arXiv:2606.21753v1 Announce Type: cross Abstract: 3D Gaussian Splatting (3DGS) has achieved state-of-the-art photorealistic rendering, but the representation ga
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Dual-Stream EEG Decoding for 3D Visual Perception
arXiv:2606.22182v1 Announce Type: cross Abstract: This paper explores a novel brain decoding model for 3D shape perception through a dual pathway architecture m
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
DreamUV: Unwrap Artist-like UV by End-to-End Flow Matching
arXiv:2606.22445v1 Announce Type: cross Abstract: UV parameterization is a fundamental step in 3D content creation, yet producing production-ready UV layouts re
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Training-Free Semantic Correction for Autoregressive Visual Models
arXiv:2606.22550v1 Announce Type: cross Abstract: Autoregressive visual models (AVMs) based on next-scale prediction have emerged as a prominent paradigm for im
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
The Power of Light: Improving Synthetic-to-Real Domain Adaptation through Physically-Based Indirect Illumination
arXiv:2606.22574v1 Announce Type: cross Abstract: While synthetic data generation resolves the manual labeling bottleneck in computer vision, minimizing the syn
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
DBT-Bleed: Dual-Branch Temporal Modeling with Key-Frame Selection for Surgical Bleeding Detection
arXiv:2606.22829v1 Announce Type: cross Abstract: Intraoperative Adverse Events (IAEs) detection is critical for improving surgical safety, with bleeding being
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
OrthoMotion:Disentangling Camera and Subject Motion via Geometry Semantics Orthogonal Attention
arXiv:2606.22835v1 Announce Type: cross Abstract: Controllable video generation demands independent command of the camera and the subject, yet 2D conditioning e
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
MotionHalluc: Diagnosing Kinematic Hallucinations in Fine-Grained Motion Reasoning
arXiv:2606.23061v1 Announce Type: cross Abstract: Motion instruction generation in cross-video comparison aims to produce corrective feedback that describes the
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Rethinking Object-Centric Representations for Video Dynamics Modeling
arXiv:2606.23436v1 Announce Type: cross Abstract: Unsupervised video object tracking aims to decompose dynamic scenes into persistent, object-centric entities w
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
Render-FM: Feedforward Model for Real-time Photorealistic Volumetric Rendering
arXiv:2505.17338v2 Announce Type: replace-cross Abstract: Photorealistic volumetric rendering of CT scans greatly benefits clinical workflows, yet neural approa
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
HaineiFRDM: Structure-Preserving Diffusion for Film Restoration under Fast Motion and Diverse Defects
arXiv:2512.24946v2 Announce Type: replace-cross Abstract: Existing film-restoration methods frequently fail under fast motion, producing limb disappearance and
ArXiv cs.AI
👁️ Computer Vision
📄 Paper
⚡ AI Lesson
1w ago
CAOA -- Completion-Assisted Object-CAD Alignment
arXiv:2606.18429v2 Announce Type: replace-cross Abstract: Accurately aligning CAD models to their corresponding objects in indoor RGB-D scans is a central chall
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2w ago
SmartDefectAI: Industrial Surface Defect Detection using Vision Transformers and Hybrid…
Computer Vision, CNN, EfficientNet, Vision Transformer (ViT), Deep Learning, Attention Mechanism, Transfer Learning, OpenCV, TensorFlow… Continue reading on Med

Forbes Innovation
👁️ Computer Vision
⚡ AI Lesson
2w ago
How AI-Powered Computer Vision Is Transforming Retail Compliance
In industries where compliance violations can directly impact customer health, this becomes incredibly important.

Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2w ago
RF-DETR: A Smaller Model That Beats the Biggest YOLO
How Roboflow’s RF-DETR transformer beats YOLO11 on COCO, skips NMS, and where the benchmark numbers deserve a closer look. Continue reading on Towards Deep Lear

Dev.to · CarCare
👁️ Computer Vision
⚡ AI Lesson
2w ago
Your Car's Paint Has a Cache Invalidation Problem — Here Is What That Means in Jaipur
cache invalidation is one of the genuinely hard problems in computer science, mostly because the...
Reddit r/MachineLearning
👁️ Computer Vision
⚡ AI Lesson
2w ago
[ECCV 2026] Paper Decision Appeals Discussion [D]
With the release of meta-reviews, ECCV sent out a google form for dissatisfied authors to submit an appeal for the following reasons: Policy errors, e.g., revie

Dev.to · CaraComp
👁️ Computer Vision
⚡ AI Lesson
2w ago
Roblox Promised "No Friction." Parents Got Locked Out — and $6.7B Vanished.
The engineering reality of biometric friction For developers building in the computer vision and...
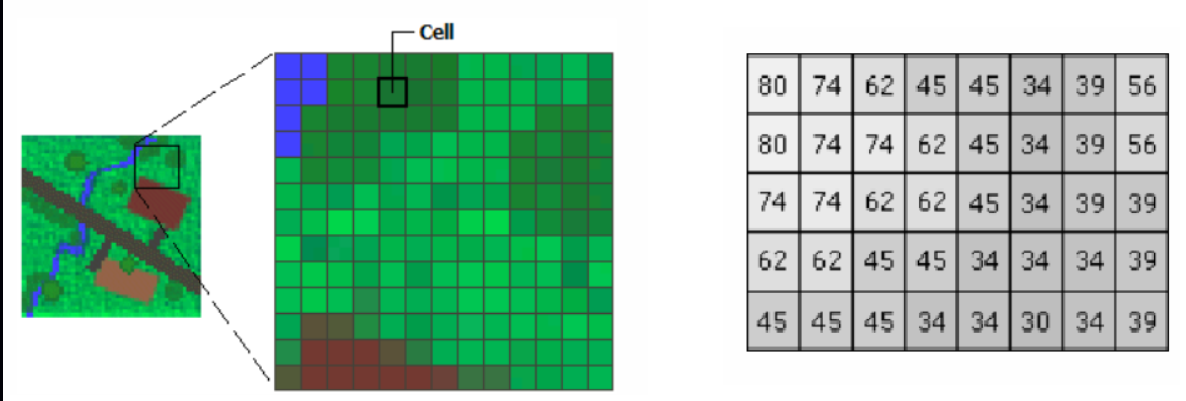
Medium · Deep Learning
👁️ Computer Vision
⚡ AI Lesson
2w ago
What is Remote Sensing?
This blog is inspired from iirs -distance learning programme by isro and iirs ( Institute of remote sensing Dehraun) which i had attended. Continue reading on M
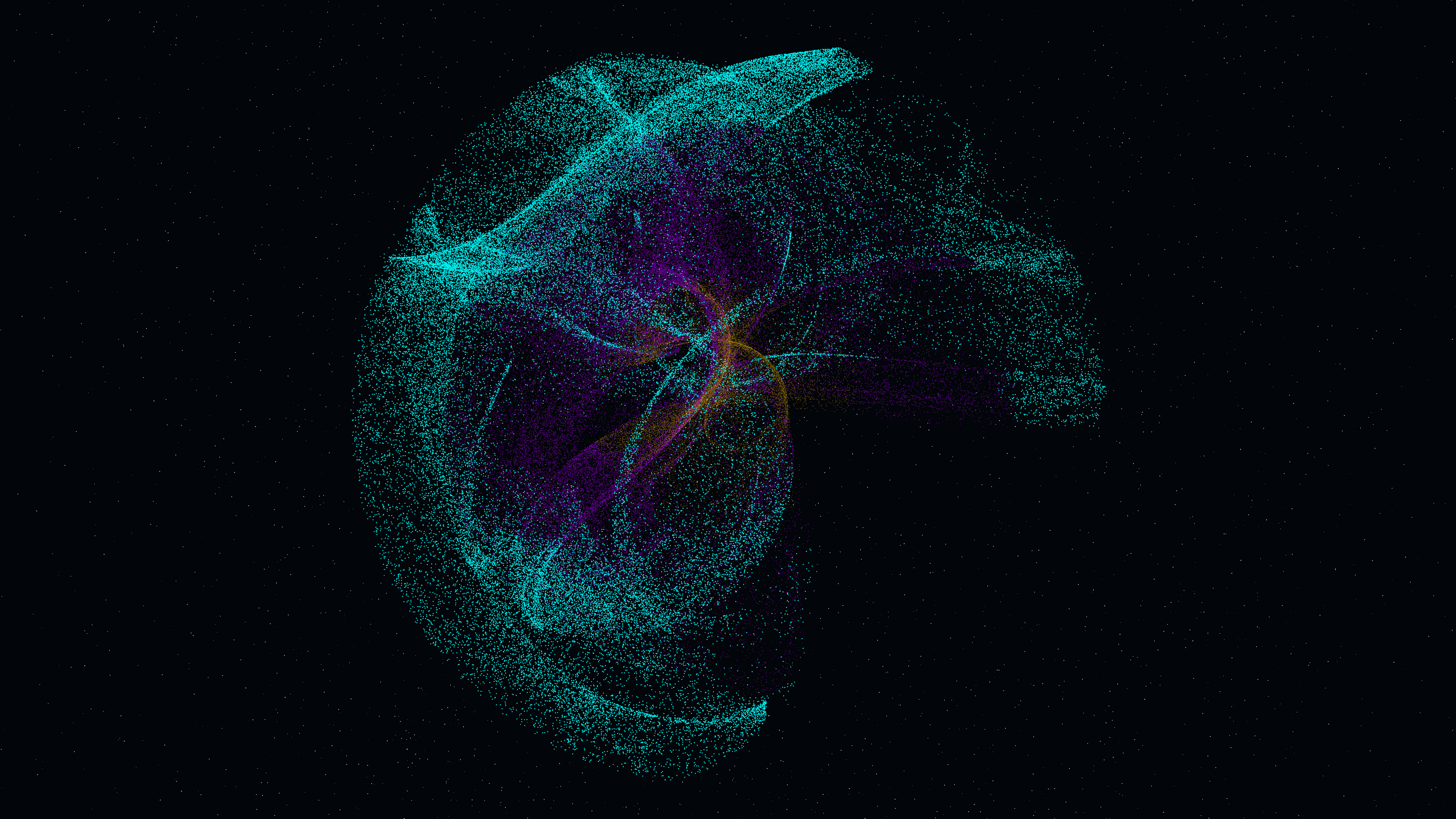
Medium · Python
👁️ Computer Vision
⚡ AI Lesson
2w ago
Clifford Vortex Filaments: Rendering Chaotic Attractors in 3D
“Clifford Vortex Filaments” is a generative media art piece that dives deep into chaos theory and non-linear dynamics, visualizing a… Continue reading on Medium
Reddit r/programming
👁️ Computer Vision
⚡ AI Lesson
2w ago
I Stored a Website in a Favicon
A small experiment of mine :) Happy to hear your thought about this submitted by /u/soupgasm [link] [comments]