Finetune LLaMa 7b on RTX 3090 GPU - Tutorial
Here is a step-by-step tutorial on how to fine-tune a Llama 7B Large Language Model locally using an RTX 3090 GPU. This comprehensive guide is perfect for those who are interested in enhancing their machine learning projects with the power of Llama 7B.
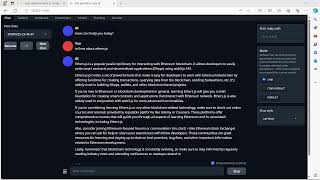
In this tutorial, I briefly walk through the entire process,setting up a Python virtual environment on your Ubuntu OS, launching a Jupyter Lab server, and connecting it to Google Colab.
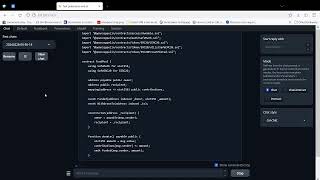
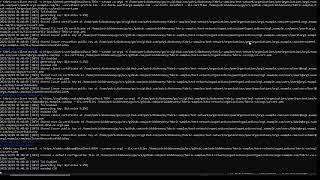
You have to install the necessary pip packages, ensuring that the NVIDIA utility CUDA is correctly installed, and that your CUDA-supporting PyTorch version can access CUDA.
The model we're training is Llama2-7B, a model with 7 billion parameters using 13 gigabytes of space. Our dataset consists of 1000 samples of question-answer and instruct prompts in multiple languages.
This was done on a Zotac Gaming Trinity OC RTX 3090 GPU which has 24GB of VRAM.
You can upload the trained model to Hugging Face and serve your model on various hosts, including Amazon Titan, GCP with Vertex AI, and NVIDIA NeMo.
For local inference, you can directly run the model using the transformers library in textgen webui. You can quantize a transformers model with jupyter notebook or quantize and convert it to one .gguf file with llama.cpp.
I got 33 tokens/s, proving that local training and inference can be viable for prototyping on llms and AI models. Thanks for watching, remember to like and subscribe!
Keywords: Llama 7B, Large Language Model, Fine-tuning, RTX 3090 GPU, Ubuntu, Pytorch
Watch on YouTube ↗
(saves to browser)
Sign in to unlock AI tutor explanation · ⚡30
Playlist
Playlist UUY0xk_A4qJTQWcV2_3sqvJw · Patrick Devaney · 11 of 15
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 9
9
 10
10
 ▶
▶
 12
12
 13
13
 14
14
 15
15

Penn Blockchain Hackathon Demo Oracle NFT Minter
Patrick Devaney
Demo Lionhacks NFT Based Content Authentication
Patrick Devaney
Aleo: Zero Knowledge Dapps - Blockchain at FIU
Patrick Devaney
Demoing a Large Language Model running locally on my laptop
Patrick Devaney
WizardCoder-1B Demo: Powerful Responsive Coding LLM at Home
Patrick Devaney
laser dolphin mixtral 2x7b dpo Q3 K M
Patrick Devaney
mixtral 2x7b Quantized 2 K prompt on machine learning
Patrick Devaney
biomistral q2k q3km q8 comparison
Patrick Devaney
SQLV2 Q4 demo
Patrick Devaney
Initializing a Hyperledger Fabric Blockchain with Docker and Ubuntu
Patrick Devaney
Finetune LLaMa 7b on RTX 3090 GPU - Tutorial
Patrick Devaney
Local InstantMesh Tiger
Patrick Devaney
groq swarms demo
Patrick Devaney
Rustifying My Repo With Swarms
Patrick Devaney
AI Agents Improve Your Code Step-by-Step | Groq + Gradio Demo
Patrick Devaney
Related AI Lessons
⚡
⚡
⚡
⚡
I Swapped All-in-One Prompts for a Modular Instruction Set (and Why You Should Too)
Medium · LLM
Is Claude 4.x Actually Smarter, or Just Hardwired to Spend?
Medium · LLM
Beyond Facts and Triggers: Closing the Gap Between “Knowing” and “Understanding” in LLM Assistants
Medium · LLM
Why your dating app conversations die after 3 messages — a technical breakdown
Medium · Startup
🎓
Tutor Explanation
