Building makemore Part 3: Activations & Gradients, BatchNorm
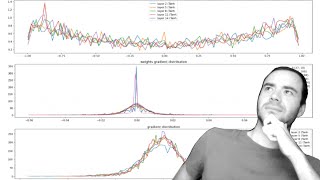
We dive into some of the internals of MLPs with multiple layers and scrutinize the statistics of the forward pass activations, backward pass gradients, and some of the pitfalls when they are improperly scaled. We also look at the typical diagnostic tools and visualizations you'd want to use to understand the health of your deep network. We learn why training deep neural nets can be fragile and introduce the first modern innovation that made doing so much easier: Batch Normalization. Residual connections and the Adam optimizer remain notable todos for later video.
Links:
- makemore on github: …
Watch on YouTube ↗
(saves to browser)
Playlist
Uploads from Andrej Karpathy · Andrej Karpathy · 9 of 17
1
 2
2
 3
3
 4
4
 5
5
 6
6
 7
7
 8
8
 ▶
▶
 10
10
 11
11
 12
12
 13
13
![[1hr Talk] Intro to Large Language Models](https://img.youtube.com/vi/zjkBMFhNj_g/mqdefault.jpg) 14
14
 15
15
 16
16
 17
17

Stable diffusion dreams of steam punk neural networks
Andrej Karpathy
Stable diffusion dreams of "blueberry spaghetti" for one night
Andrej Karpathy
The spelled-out intro to neural networks and backpropagation: building micrograd
Andrej Karpathy
Stable diffusion dreams of tattoos
Andrej Karpathy
Stable diffusion dreams of steampunk brains
Andrej Karpathy
Stable diffusion dreams of psychedelic faces
Andrej Karpathy
The spelled-out intro to language modeling: building makemore
Andrej Karpathy
Building makemore Part 2: MLP
Andrej Karpathy
Building makemore Part 3: Activations & Gradients, BatchNorm
Andrej Karpathy
Building makemore Part 4: Becoming a Backprop Ninja
Andrej Karpathy
Building makemore Part 5: Building a WaveNet
Andrej Karpathy
Let's build GPT: from scratch, in code, spelled out.
Andrej Karpathy
[1hr Talk] Intro to Large Language Models
Andrej Karpathy
Let's build the GPT Tokenizer
Andrej Karpathy
Let's reproduce GPT-2 (124M)
Andrej Karpathy
Deep Dive into LLMs like ChatGPT
Andrej Karpathy
How I use LLMs
Andrej Karpathy
